101 Chrome Exploitation — Part 0: Preface
This will be an introductory course to exploiting browsers. Not just covering a few JIT bugs and common renderer process exploits, we'll take an in-depth look at the entire browser structure, security layers and understand how a chain is built, how to assemble each part and turn memory corruptions or invalid states into exploits. And there's no better way than an introduction analyzing a complete functional full-chain up to Chrome 130!
Don't worry about understanding everything described in this preface, all the subjects covered here are for demonstration purposes only; in future articles, we'll go into more detail on each of the topics presented here. As a prerequisite you only need to have a basic knowledge of exploitation (ROP, heap corruptions such as UAF, heap-overflow, etc.) and general computer architecture (what processes are, general OS functions, OS interactions, etc.).
What will be covered
Browser Architecture Fundamentals
- Browser architecture
- Analyze process models
- Identify attack surfaces in browser components
Topics Covered
- Core Browser Components
- - Rendering engine architecture (Blink, Gecko, WebKit)
- - JavaScript engines (V8, SpiderMonkey, JavaScriptCore)
- - Network stack implementation
- Process Models and Isolation
- - Multi-process architecture evolution
- - Privilege separation boundaries
- Memory Management
- - Heap allocators in browsers (PartitionAlloc, Oilpan, jemalloc)
- - Garbage collection strategies
- - Exploitation techniques and protections
- JavaScript Engine Internals
- - JIT compilation pipeline
- - Type systems and optimizations
Practical Exercises
- Extract simple dump and identify objects from a specific cache, understanding the layout in memory from the debugger.
Common Browser Vulnerability Patterns
- Identify and classify browser vulnerabilities
- Understand vulnerability root causes
- Analyze real-world browser bugs
Topics Covered
- Memory Corruption Vulnerabilities
- - Use-after-free patterns and triggers
- - Buffer overflow scenarios in browsers
- - Type confusion in JavaScript engines
- - Heap corruption techniques
- Logic Flaws and Design Issues
- - Invalid states
- - Discrepant implementation with Spec
- Parser Vulnerabilities
- - HTML, CSS parsing edge cases
- - JavaScript parser exploitation
- - SVG and XML parsing corruptions
- Concurrency Issues
- - Race conditions in multi-process browsers
- - Time-of-check-time-of-use (TOCTOU) bugs
- - Worker thread vulnerabilities
Practical Exercises
- CVE analysis and reproduction
- Root cause analysis practice
Case Studies
List of CVEs, I'll choose interesting cases carefully.
Renderer Process Security
- Master renderer process attack surface
- Analyze web API vulnerabilities
Topics Covered
- DOM and Rendering Pipeline
- - DOM tree manipulation
- - Layout engine system
- Javascript surface
- - Javascript attack surface
- - V8 sandbox bypasses
- - WebAssembly security
- Web APIs
- - WebGL vulnerabilities
- - WebRTC vulnerabilities
Practical Exercises
- WebAPI and JS exploit development for renderer process.
Case Studies
List of CVEs, I'll choose interesting cases carefully.
Sandbox Architecture and Bypasses
- Understand sandbox implementation details
- Analyze sandbox escape techniques
- Mitigation effectiveness
Topics Covered
- Sandbox Implementations
- - Chrome's sandbox architecture
- - Firefox sandbox evolution
- - Windows integrity levels
- - Linux seccomp-bpf filters
- IPC Security
- - Mojo IPC in Chromium
- - Privileged service interfaces
- Sandbox Escape Techniques
- - Logical sandbox bypasses
- - Kernel exploitation from sandbox
- - IPC vulnerability exploitation
- Mitigation Technologies
- - MiraclePtr
Practical Exercises
List of CVEs, I'll choose interesting cases carefully.
Case Studies
- Full chain exploits analysis
- Pwn2Own sandbox escapes
- Project Zero research findings
Browser Exploitation Techniques
Topics Covered
- Exploitation Primitives
- - Heap spray techniques evolution
- - Arbitrary read/write primitives
- - Control flow hijacking
- Modern Mitigation Bypasses
- - ASLR bypass strategies
- - DEP/NX circumvention
- - CFI/CFG bypass techniques
- - Isolated heap attacks
- Exploit Development Process
- - Vulnerability analysis workflow
- - Exploit reliability techniques
- - Debugging methodologies
- Advanced Techniques
- - JIT spray variations
- - Return-oriented programming in browsers
- - JavaScript exploitation helpers
- - Multi-stage exploit chains
Practical Exercises
- Development of exploits for some of the CVEs analyzed above
Case Studies
- Project Zero blogs from real-world exploits catch ITW.
Why browsers?
I won't go into too much of this topic as it's a bit clear, but it's always good to point out how critical the attack surface of browsers is and how powerful a chain can be. Chrome alone currently has 3.45 billion users worldwide, making it the most widely used browser. This massive user base means that browser vulnerabilities can potentially affect billions of devices across various platforms (desktop or mobile). Additionally, the complexity of modern browsers, with their multiple processes, JavaScript engines, rendering pipelines, etc. creates a vast attack surface with numerous potential entry points for exploitation.
The state of the chains
In the last decade, browser security has gone from a game of a single bug to a complex game that requires several synchronized attacks. What used to require researchers to find a single memory corruption bug now requires specialized knowledge of JavaScript mechanisms, compiler optimizations, inter-process communication and internal aspects of the operating system.
The Evolution of Browser Security
In 2008, Chrome introduced a revolutionary multi-process architecture that changed browser security forever. Each tab runs in its own sandboxed process, meaning that compromising JavaScript execution no longer meant game over. This forced attackers to evolve, leading to today's reality where a full compromise requires chaining together multiple vulnerabilities across different components.
Consider how the landscape has shifted over the years. From 2008 to 2012, a single bug could mean full compromise. The game changed between 2013 and 2018 when two bugs became the minimum requirement, one for the renderer and another for sandbox escape. By 2024, three or more bugs became standard as V8 introduced its own internal sandbox, and now in 2025, we commonly see chains requiring four or more vulnerabilities as additional mitigations demand ever more creative bypasses.
Why So Many Bugs?
Let me show you what we're up against. This is a example from the Chrome implementation of "defense in depth" in Desktops (at Android the GPU also have unrestricted access to the SO):
+-------------------------------------------------------------------------+
| Chrome Browser |
| |
| +----------------------------+ +-----------------------------+ |
| | Renderer Process | | Browser/main Process | |
| | [No access to OS] | | | |
| | +----------------------+ | | | |
| | | V8 Sandbox | | | | |
| | | | | | [Unrestricted access to OS] | |
| | | [JavaScript Code] | | | | |
| | | | | | | |
| | +----------------------+ | | | |
| +------------+---------------+ +-----------------------------+ |
| ^ ^ |
| | IPC/Mojo | |
| +---------------+--------------------+ |
| | |
| +---------------+ |
| | |
| V |
| +------------+---------------+ |
| | GPU Process | |
| | | |
| | [Restricted access to OS] | |
| | | |
| +----------------------------+ |
| |
+-------------------------------------------------------------------------+The first layer is the renderer process itself. Every website runs in an isolated renderer process with minimal privileges. This process cannot access files on your computer, make direct system calls, or communicate with other programs. It can only talk to the browser through specific IPC channels. Think of it as a maximum-security prison cell, the JavaScript code can run, but it can't reach anything important.
Within the renderer process, the V8 JavaScript engine now has its own internal sandbox, introduced in 2024. This sandbox isolates JavaScript objects from raw memory access and prevents heap corruption from directly achieving code execution. To escape, attackers must corrupt specific "trusted" objects that bridge the sandboxed and unsandboxed worlds.
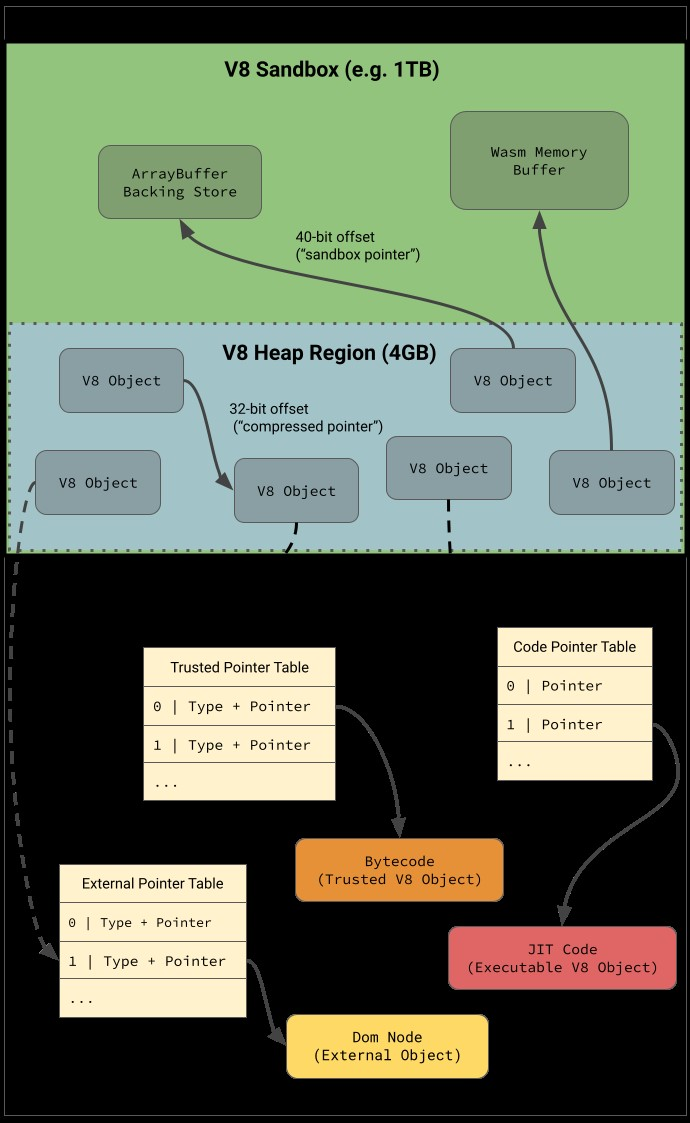
The renderer process itself runs under strict operating system controls that form the Chrome sandbox. On Windows, this means restricted tokens and integrity levels. Linux uses Seccomp-BPF filters to limit system calls. macOS employs sandbox profiles for similar restrictions. Across all platforms, file system access is severely limited. Even if you fully control the renderer, you're still trapped within these OS-level restrictions.
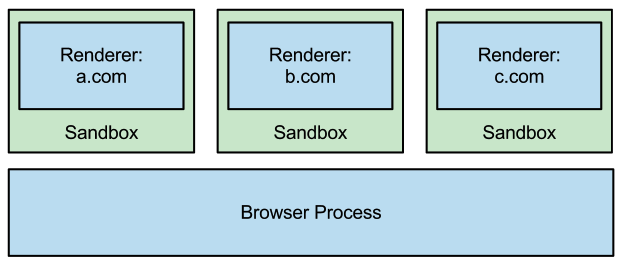
So we can say that the architecture is like: even if you pwn the JavaScript engine, you're still inside a cage. Even if you escape from that cage, you'll still be in a sandbox. And even when you escape from that sandbox, you'll just be a normal process with limited privileges (which will require another kernel exploit to fully pwn the device, but that's outside the current focus).
Looking at this architecture, it seems quite intimidating, right?
A modern chain
I know it may seem practically impossible or that only the "lucky ones" would be able to set up a full-chain after seeing all those layers of security and complex mitigations, but that's not true. As our first exercise, let's look at some recently reported bugs (2024 and 2025) and see how it's perfectly possible to find and develop full-chains even today.
Stage 1: Initial memory corruption, CVE-2025-0291
link to the issue: https://crbug.com/383356864
Our journey begins with a type confusion vulnerability in V8's newest compiler, Turboshaft, specifically in how it analyzes types for WebAssembly Garbage Collection. This bug occurs because Turboshaft optimizes WebAssembly code by analyzing types through control flow, but in single-block loops, the type analyzer makes incorrect assumptions. This seemingly small oversight leads to type confusion between WasmGC reference types, allowing us to make V8 treat a numeric value as an object pointer.
The exploitation impact is significant. We gain arbitrary read capabilities, allowing us to read any address in the V8 heap. We also achieve arbitrary write, enabling modification of any object in the V8 heap. With these capabilities, we can build fundamental exploitation primitives: addrOf to get an object's address and fakeObj to create fake objects at arbitrary locations. Most importantly, we can now target JIT-compiled code for modification.
WebAssembly type confusion bugs are particularly powerful for several reasons. The WebAssembly type system is simpler than JavaScript's, making bugs more straightforward to exploit. The optimization phases have less complexity to verify, leading to more reliable vulnerabilities. These bugs trigger reliably without complex heap manipulation, and they provide strong primitives that serve as perfect building blocks for the next stage of our exploit.
Stage 2: V8 Sandbox escape, issue 379140430
link to the issue: https://crbug.com/379140430
With control over the V8 heap, we now face the challenge of escaping V8's internal sandbox. This is where our second bug comes into play, a signature type confusion in the WebAssembly-to-JavaScript wrapper functions.
Chrome creates wrapper functions to facilitate calls between WebAssembly and JavaScript code. During tier-up optimization, when these wrappers are compiled to more efficient versions, signature mismatches can occur. The bug exploits this process to corrupt a Tuple2 object that lives in "trusted" memory. These Tuple2 objects are special because they contain raw 64-bit pointers that aren't subject to sandbox restrictions.
The V8 sandbox operates by compressing most object pointers and isolating them from raw memory access. However, some objects must live in "trusted" space with full 64-bit pointers to bridge the gap between sandboxed and unsandboxed memory. Tuple2 objects serve this bridging function, and corrupting them gives us read/write access outside the sandbox.
The exploitation strategy leverages the V8 heap primitives from stage one to locate wrapper functions. We then trigger tier-up optimization with specific timing to cause the signature mismatch. By corrupting the Tuple2 to point outside the V8 heap, we build new primitives for renderer process memory access. This bug is perfect for our purposes because it's specifically designed as a sandbox bypass. The Tuple2 corruption is reliable and doesn't require complex heap layouts, and the arbitrary read/write primitive it provides in the renderer process is essential for our final stage.
Stage 3: Sandbox escape, CVE-2024-11114
link to the issue: https://crbug.com/370856871
The final and perhaps most creative bug in our chain turns a UI feature into a sandbox escape. Chrome's drag-and-drop functionality is handled by a Mojo IPC interface, with the startDragging() method intended for legitimate drag operations. However, this method could be called directly from a compromised renderer, allowing programmatic control of mouse movements and clicks.
Our escape method is elegantly simple. We use our renderer process control to prepare a malicious file download, then call startDragging() to simulate user drag-and-drop actions. By programmatically "dragging" the file to a location that triggers execution, we convince the OS to execute our file, giving us code execution outside Chrome.
What makes this bug special is that no memory corruption is needed for this stage. Instead, it abuses legitimate functionality in an unintended way, bypassing many traditional sandbox escape mitigations. This demonstrates that sandbox escapes aren't always about memory corruption and sometimes the most effective exploits abuse the trust boundaries between components. UI features can become security vulnerabilities when they're accessible from compromised contexts. The relative simplicity of exploitation, once you have renderer process control, makes this bug particularly valuable. It provides reliable code execution without the complexity of ROP chains or other traditional techniques.
The Complete Exploitation Flow
Let's trace through the complete attack from start to finish. The attack begins with the initial setup phase, where we serve a malicious webpage embedded with a carefully crafted WebAssembly module. The page includes JavaScript to trigger the vulnerability.
In phase two, we compromise the renderer using CVE-2025-0291. We create a WebAssembly module with specific type patterns designed to confuse Turboshaft's analyzer. By triggering optimization on the vulnerable function, we exploit the type confusion to read V8 heap memory. We then locate important objects like maps, functions, and arrays, building our fundamental addrOf and fakeObj primitives. With these tools, we achieve arbitrary read/write capabilities within the V8 heap.
Phase three involves escaping the V8 sandbox using Issue 379140430. We locate WebAssembly-to-JavaScript wrapper functions and create the precise conditions needed for tier-up optimization. By triggering a signature mismatch during this optimization, we corrupt a Tuple2 object in trusted space. This corrupted object becomes our bridge to the outside world, providing read/write access beyond the sandbox boundaries. We use this capability to locate crucial browser process structures.
In phase four, we escape the Chrome sandbox entirely using CVE-2024-11114. We search through browser process memory to find Mojo interface pointers, then prepare a malicious executable for download. By calling the startDragging() interface and simulating drag-and-drop actions to an execution location, we achieve code execution outside the Chrome sandbox.
The final phase involves executing our payload with user privileges, cleaning up exploitation artifacts to avoid detection, and maintaining access for demonstration purposes. Each phase builds upon the previous one, creating a complete chain from visiting a website to achieving system compromise.
Tools and Environment Setup
Working with this exploit chain requires a specific set of tools and configurations. You will need a Chrome 130 in either release or development version. You can find the exe to install the release version here. For debugging, you'll need WinDbg along with the Chrome symbols. In next articles, we'll discuss how to set up the complete environment to debug any version with the correct symbols on Windows and Linux. For now, you can just concentrate on running the exploit and seeing how it works.
To download and provide the files, just follow these commands:
# You can use any http server
C:\Users\r>npm install -g http-server
...
C:\Users\r>git clone https://github.com/Petitoto/chromium-exploit-dev
C:\Users\r>cd chromium-exploit-dev
C:\Users\r\chromium-exploit-dev>http-server -p8000 -c-1Now just open the Chrome at http://localhost:8000/ and see the logs from the exploit working.
Conclusion
Modern Chrome exploitation represents the pinnacle of software security research. It requires deep technical knowledge, creative thinking, and meticulous attention to detail. Through this course, you'll gain not just the ability to understand existing exploits, but the skills to discover and develop your own.
Remember that every security researcher started exactly where you are now. The seemingly impossible complexity becomes manageable when broken down into components and studied systematically. With dedication and practice, you too can master the art of browser exploitation.
Ready to begin? Let's dive into the code.
References and study resources
- Chromium Security, Core Principles: https://www.chromium.org/Home/chromium-security/core-principles/
- Chromium Sandbox Design docs: https://chromium.googlesource.com/chromium/src/+/main/docs/design/sandbox.md
- Chromium Site Isolation Design Document: https://www.chromium.org/developers/design-documents/site-isolation/
- Toolkit for Chromium full-chains: https://github.com/Petitoto/chromium-exploit-dev
- Issue discussions
- V8 corruption: https://crbug.com/383356864
- V8 sbx escape: https://crbug.com/379140430
- Browser sbx escape: https://crbug.com/370856871
Author: 3074e822993c84cdf216428e1f1e8f570c9626544872f2ed4c291befc72770e3